
La explotación de los fallos de seguridad en las arquitecturas de software no siempre viene determinada por las vulnerabilidades descubiertas en las tecnologías usadas para construir el sistema, sino también por el deficiente diseño por parte de analistas y/o malas prácticas y anti patrones usados por los propios desarrolladores. Es común encontrar programadores que todavía usan las tecnologías obsoletas, se sienten cómodos incrustando código Java dentro de las páginas JSP, o están usando operadores del propio lenguaje para concatenar los parámetros de las consultas / sentencias SQL y un largo etcétera de disparates. Incluso en las arquitecturas en capas, la ausencia de patrones de diseño tiene como resultado un sistema altamente acoplado y difícilmente escalable. Además, la capa de negocio empieza a delegar las responsabilidades impropias, como el manejo de transacciones, auditoría, seguridad – concerns transversales que se deberían encapsular y aplicar de forma transparente.
Las consecuencias de todo esto a largo plazo pueden llegar a ser realmente caóticas. El mantenimiento y la implementación de nuevos requisitos funcionales cada vez se vuelve más complicado, haciendo que el número de fallos y vulnerabilidades para comprometer el sistema se multiplique. Hacer software de gran calidad y aplicar la integración continua, desde luego no es tarea trivial, aun menos, hoy en día, cuando los usuarios cada vez son más exigentes y piden aplicaciones más potentes, rápidas y flexibles.
¿Quizás haya llegado el momento de cambiar el enfoque tradicional de desarrollo de software? Eso es lo que efectivamente persigue CQRS. Detrás de estas siglas (Command Query Responsability Segregation) se esconde un patrón arquitectónico con un fundamento inicial muy sencillo: separar la aplicación en dos partes – una que se responsabiliza de ejecutar acciones y otra encargada de lanzar las consultas. Aunque a primera vista puede parecer algo irrelevante, este enfoque nos abre una plétora de posibilidades. Para comprender mejor el paradigma CQRS, vamos a explicar cada uno de los componentes que lo forman ayudándonos del siguiente gráfico.
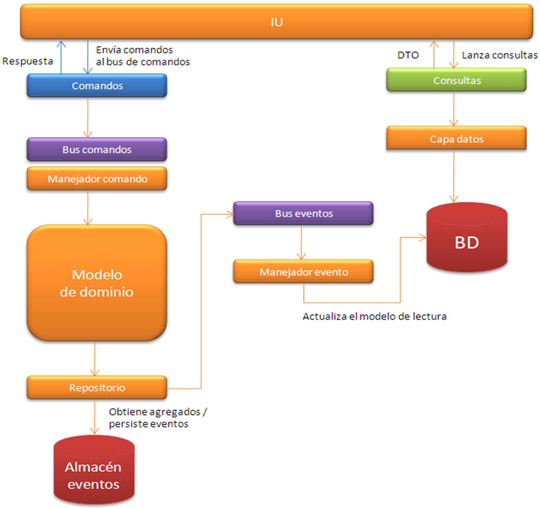
- Comandos – son objetos que encapsulan tanto la intención del usuario como la información necesaria para llevar a cabo la operación. Por ejemplo: CreateNewUserCommand. Los comandos se envían al bus de comandos que se encargará de despachar cada comando a su correspondiente manejador. El cambio de estado en el sistema se inicia mediante la ejecución del comando.
- Modelo de dominio – representa el corazón del sistema. Debido a que CQRS está basado en su predecesor DDD (Domain Driven Design) el enfoque principal de diseño reside sobre el modelo de domino no anémico. ¿Qué quiere decir esto? En el diseño tradicional, los objetos de dominio suelen desempeñar el rol de entidades que tan solo guardan el estado del sistema y carecen de cualquier tipo de comportamiento. Esto además suele crear ambigüedad entre los DTO (Data Transfer Objects) y los objetos del modelo, haciendo que estos últimos acaben teniendo información que se debe renderizar en la vista, y por lo tanto crear acoplamiento. Otra capa de servicios se dedica a alterar el estado del sistema. CQRS promueve un diseño enfocado completamente al modelo de dominio estrictamente de comportamiento.
- Repositorios – proporcionan el acceso a los objetos de dominio y permiten aislar el modelo de dominio del mecanismo de persistencia. Los repositorios tan solo tienen que ser capaces de recuperar el agregado (objeto de dominio) a partir de su identificador único, mientras cualquier otro tipo de consulta se realizará sobre la base de datos de consultas.
- Eventos – son la fuente de cualquier cambio de estado en la aplicación. Como hemos mencionado anteriormente, la ejecución de los comandos sobre el agregado, inicia el cambio de estado en el sistema, lo que a su vez producirá una serie de eventos de dominio. Aun más, ni siquiera deberemos persistir los objetos del dominio sino los eventos que se generan. Con esto tenemos la posibilidad de reconstruir el objeto de dominio a su último estado, tan solo aplicando el flujo de eventos sobre él. Este patrón se conoce como eventsourcing. Los eventos se mandan al bus de eventos, y se despachan a cualquier componente interesado.
- Almacén eventos – se encarga de dar soporte a los eventos de dominio, es decir, gestionar su almacenamiento.
- Consultas – una sencilla capa de servicios se encarga de recuperar los datos y rellenar la vista. La información que se desea renderizar en la vista se reflejará en el objeto DTO que contendrá los resultados de la consulta.
Con los conceptos un poco más claros, veamos que ventajas nos ofrece CQRS:
2. Alta disponibilidad a nivel de aplicación – si se cae un componente el resto del sistema puede seguir funcionando.
3. Auditoría / historial / traza de las acciones de usuarios “out of the box“. Este tipo de auditoría no es comparable a ninguna infraestructura de log – los eventos aportan valor al negocio. Es fácil nutrir a plataformas de auto aprendizaje o motores de correlación a partir de estos eventos, para por ejemplo predecir las acciones del usuario, detectar anomalías, etc. Al tener la traza de todo lo que ocurre en la aplicación, tenemos una fuente de verdad única. La reproducción de fallos se hace más sencilla.
4. En vez de enlazar los objetos de dominio con los componentes de la UI, tenemos simples DTO que reflejan fielmente aquello que se quiere representar en la vista y se pueden recuperar directamente desde la base de datos. Así, podemos obtener toda la información necesaria en una única petición a la fuente de datos.
5. CQRS ayuda a escribir un modelo de dominio expresivo.
6. Cuando se necesita que un objeto de dominio procese un comando, el repositorio obtendrá el flujo de eventos relacionados con ese objeto del almacén de eventos. Entonces, se instanciará un nuevo objeto y se aplicarán todos los eventos sobre él. De esta forma, obtendremos el objeto en su estado original y no hará falta proporcionar persistencia para el modelo de dominio.
7. Modelos de datos separados. Éstos se mantienen consistentes, sincronizados y desacoplados gracias a los eventos que además proporcionan mecanismo para actualizar el modelo de lectura. Para el modelo de lectura podemos usar cualquier tecnología, desde JDBC, pasando por sistemas ORM, hasta soluciones NoSQL, ya que la única finalidad es rellenar la vista con datos lo más rápido posible. Podemos tener bases de datos denormalizadas para optimizar las lecturas e evitar realizar complejas consultas con muchas uniones.
Como ninguna tecnología es perfecta y válida para todas las soluciones, lo mismo pasa con CQRS. Estos son los puntos que se deben tener en cuenta si decidimos aplicar CQRS en nuestras aplicaciones:
2. La curva de aprendizaje es relativamente alta y requiere cambiar la perspectiva sobre el diseño tradicional.
3. Mayores requerimientos de la infraestructura al tener dos modelos (lectura y escritura).
En el resto de casos, los beneficios de CQRS son enormes y las aplicaciones serán mucho más mantenibles, fácilmente extensibles y preparadas para los nuevos retos que cada día nos plantean las tecnologías / usuarios. La próxima vez veremos como aplicar CQRS en una aplicación sencilla usando Axon Framework. Con esto, asentaremos mejor todos los puntos teóricos vistos anteriormente.
Que puedo decir? Cuando comenzamos ;) ?