
En el artículo anterior Ángela ya tenía gracias al análisis forense toda la información del ataque, así que le toca continuar con la respuesta al incidente en las fases de contención, erradicación y recuperación.
Respuesta al incidente
Con todas las respuestas importantes en la mano, Ángela puede hacer un esquema muy rápido del incidente:
- Los atacantes envían un spear-phishing a Pepe Contento y otros altos cargos el 3 de noviembre sobre las 10.37h.
- El usuario Pepe Contento abre el correo y pincha sobre el enlace el mismo día a las 11.05h, ejecutando el código malicioso entregado por Sharpshooter y comprometiendo su equipo con una sesión de Meterpreter.
- Los atacantes verifican que tienen privilegios de administrador y obtienen las credenciales del equipo, encontrando el hash de un administrador de dominio (que tenía sesión iniciada en el equipo).
- Los atacantes se hacen pasar por la cuenta de administrador de dominio y acceden a las contraseñas cifradas de varios altos cargos.
- Estas contraseñas cifradas son rotas por los atacantes mediante un ataque de fuerza bruta, obteniendo las contraseñas en claro.
- Los atacantes emplean esas credenciales para acceder a los webmail de diversos altos cargos entre las 11.30h y las 16.00h del mismo día.
- A las 15.30h la usuaria maria.feliz detecta un comportamiento inusual de su cuenta de correo y lo comunica al CAU.
- A las 15.45h el CAU corrobora el comportamiento extraño y avisa a Seguridad.
- Seguridad accede a las 15.55h a los logs del correo y detecta los accesos anómalos.
- Se declara incidente de seguridad a las 16.00h.
Bajo esta hipótesis la contención del incidente es bastante clara: el equipo de pepe.contento está apagado, por lo que no supone en estos momentos una amenaza. La contención inicial se reduce a forzar un cambio de contraseñas de todos los usuarios cuyas cuentas de correo han sido accedidas, así como bloquear en el cortafuegos todos los dominios pertenecientes a *.mina.es (para evitar futuros ataques por esta vía).
Siendo previsores, Ángela bloquea también las direcciones IP implicadas, creando además en el IDS reglas que permitan detectar el acceso tanto a las mismas como a cualquier dominio *.mina.es (para de esta forma detectar un futuro ataque aunque este no pueda progresar al estar bloqueado en el cortafuegos).
En este caso la contención y la erradicación se ejecutan en el mismo paso ya que Ángela ha esperado a hacer un “cierre perfecto” obteniendo toda la información necesaria de los atacantes (y también a que ha tenido suerte habiendo detectado el ataque en su fase inicial y evitando que los atacantes hubieran afianzado su posición).
Una erradicación en profundidad requiere de dos tareas adicionales: en primer lugar, Ángela está prácticamente segura que los atacantes han tenido acceso a un controlador de dominio, por lo que es posible que hayan robado TODOS los hashes de los usuarios. Por ello, y con pena de corazón (y de los usuarios), Ángela ordena forzar un cambio de contraseñas de los 5000 usuarios del MINAF.
La segunda tarea es mucho más compleja: los atacantes pueden haber empleado su acceso al controlador de dominio para dejar “regalos” como un Golden Ticket o una Skeleton Key. Ángela decide curarse en salud y ejecutar un doble reseteo de la cuenta KTBTGT (para invalidar el Golden Ticket) y reiniciar el controlador de dominio (para borrar la Skeleton Key de la memoria del servidor). Decide de forma adicional tenerlo bajo vigilancia durante al menos un par de semanas revisando todos los eventos y accesos para asegurarse de que está completamente limpio.
Le queda como tarea pendiente revisar el servidor de correo Microsoft Exchange, ya que cabe la posibilidad de que los atacantes lo hubieran comprometido con Ruler u otra herramienta similar. Ángela decide monitorizar los logs del Exchange en busca de accesos a las cuentas de los altos cargos desde direcciones IP fuera de España.
Lecciones aprendidas
El tiempo de detección (<6h) y de respuesta al incidente (< 10h) es inmejorable para un incidente de estas características. Sin embargo, todo incidente de seguridad tiene una fase de lecciones aprendidas en la que se analiza el incidente y se identifica qué podemos hacer mejor para evitar que se produzca un incidente similar, así como mejorar nuestra capacidad de respuesta a incidentes.
En el caso del incidente, Ángela y Salvador se reúnen con el CIO del MINAF y le proponen las siguientes acciones de mejora:
- Mejorar la concienciación: Aunque es cierto que el incidente ha sido detectado con rapidez gracias a una usuaria, se ha producido por culpa de las acciones de otro usuario. Identificar a los usuarios que necesitan un refuerzo de concienciación en seguridad y proporcionárselo debería de ser prioritario.
- Mejorar la comunicación entre áreas: El CAU no tendría que haber dado privilegios de administrador local a los altos cargos sin la autorización de Seguridad de la Información. Es necesario establecer procedimientos para que los cambios críticos tengan que ser aprobados (o como mínimo consultados) con las áreas directamente afectadas.
- No usar cuentas de administrador de dominio para la gestión de equipos de usuario: Es una batalla frecuente en las grandes organizaciones, pero se debe establecer una estructura en capas (como indica Microsoft en su documento de medidas contra ataques de movimiento lateral) en la que los grupos con privilegios más sensibles no accedan a equipos con menos privilegios para prevenir de esta forma el robo de hashes.
- Cuentas de usuario sin privilegios de administrador: Los usuarios no deberían de tener privilegios de administrador en sus cuentas de forma habitual, salvo contadas ocasiones y siempre de forma totalmente justificada. De esta forma se fuerza a un atacante a escalar privilegios, algo que puede bloquear su ataque o facilitar su detección.
- Contraseñas robustas: Unas contraseñas robustas (12+ caracteres, mezclando mayúsculas, minúsculas, números y símbolos de puntuación, sin usar palabras de diccionario) no son la panacea, pero aumentan el coste del ataque para los atacantes (bien en tiempo o en dinero).
- Activar SPF: Una forma muy sencilla de verificar el origen de un correo es activar la verificación SPF (Sender Policy Framework), un protocolo de seguridad que se monta encima de SMTP y que nos permite detectar correos con el origen falsificado (en este caso bloqueando el correo con el origen rrhh@minaf.es.
- Desplegar 2FA en el webmail: Todos los accesos externos del MINAF deberían estar protegidos por un segundo factor de autenticación, de tal forma que aunque un atacante se hiciera con las credenciales no pudiera acceder al correo.
Bonus Extra 1: Sysmon
Imaginemos que Ángela hubiera podido desplegar algún tipo de herramienta de monitorización del puesto de trabajo (endpoint). En nuestro caso ponemos como ejemplo Sysmon, un software de Microsoft que permite monitorizar una amplia gama de la actividad de un equipo (creación de procesos, conexiones, modificación del registro, etc…).
Sysmon guarda toda la información de su operación en un log de eventos: Sysmon/Operational, por lo que se puede consultar la información recogida con el Visor de Eventos.
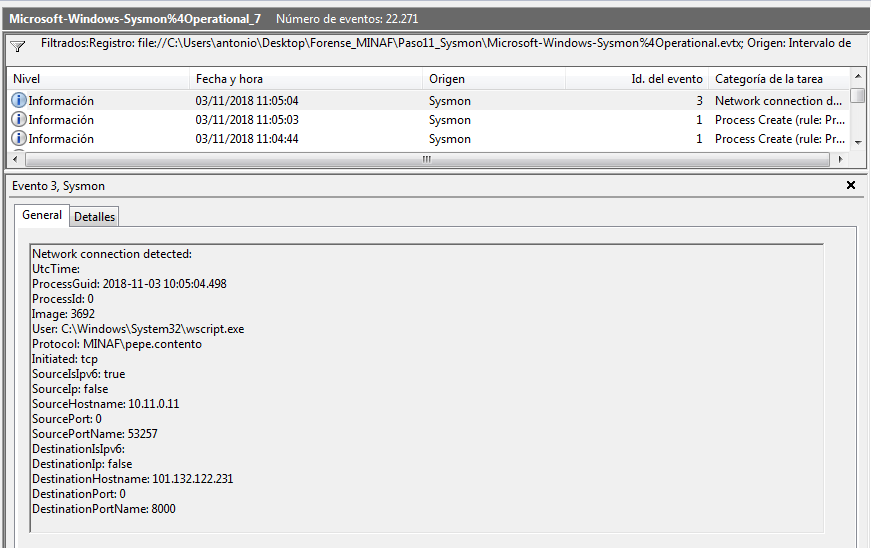
Si el equipo de pepe.contento hubiera tenido Sysmon desplegado, Ángela lo habría tenido muy fácil para detectar la intrusión. Aquí tenemos la conexión inicial de wscript.exe ejecutando el contenido del enlace malicioso:
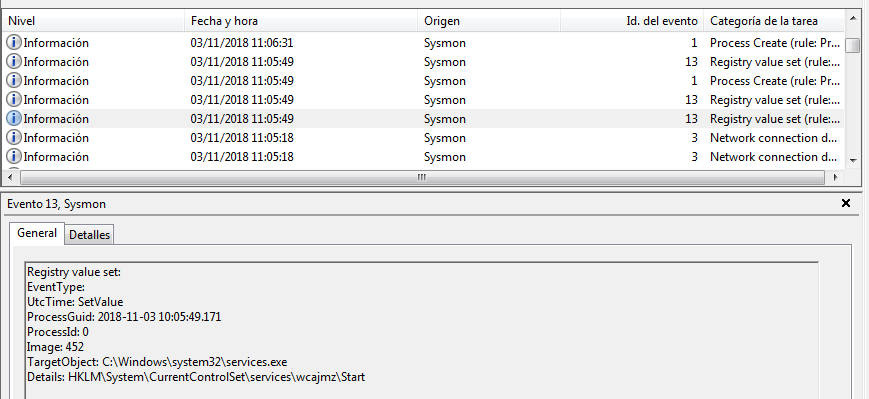
Aquí la creación en el registro de Windows del servicio malicioso con nombre aleatorio:
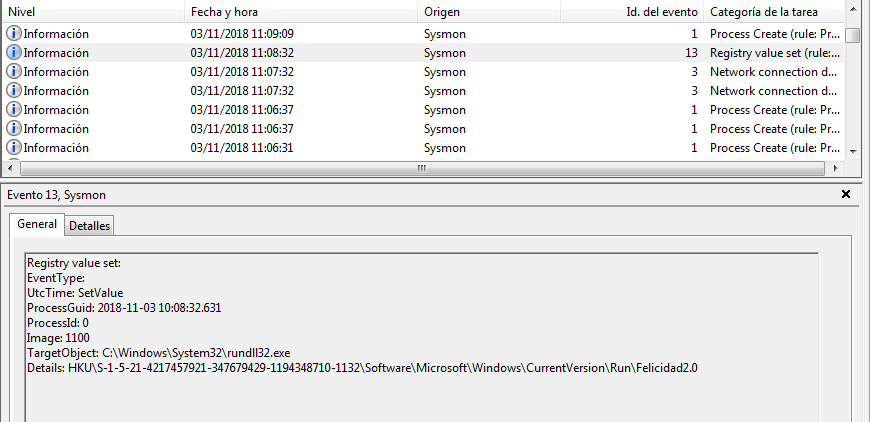
Y aquí el establecimiento de la clave de registro para la persistencia de los atacantes:
Como se puede observar, Sysmon permite detectar diversas fases de la ejecución del malware. Si además, centralizamos la salida de Sysmon en un servidor externo, tenemos un potencial tremendo para detectar ataques dirigidos. Y si además, disponemos de analizadores especializados para automatizar todo el proceso (como en la herramienta CARMEN desarrollada entre el CCN-CERT y S2 Grupo), tenemos sin duda una herramienta muy potente para complicarle la vida a los atacantes.
Bonus Extra 2: ¿Y si los malos fueran muy listos?
Este incidente ha tenido una resolución feliz (y sobre todo, rápida). Pero imaginamos otro escenario en el que los atacantes hubieran sido especialmente competentes, tomando diversas contramedidas para dificultar su detección. Algunas acciones que podrían haber tomado serían:
- Reiniciar el equipo de pepe.contento: De esta forma se habría perdido por completo el contenido de la RAM, por lo que no podríamos saber fácilmente ni la vía de entrada ni las acciones realizadas por el atacante.
- No dejar persistencia en memoria: No lo podríamos localizar en el registro ni obtener información sobre el malware empleado por los atacantes.
- Smash & Grab: Si los atacantes solo quisieran las credenciales, podrían hacer el ataque al DC (DCSync/NTDIS.dit) y reiniciar el equipo de pepe.contento sin dejar persistencia. El único rastro es la (escasa) navegación web por el dominio malicioso.
- Los atacantes, una vez conseguidos sus objetivos, tiran el servidor web de sharepoint.mina.es: no tendríamos el contenido de los felicidad* y no podríamos saber qué malware ha sido empleado para comprometer el equipo (tan solo los accesos en los logs del proxy de navegación).
- Los atacantes borran el correo del cliente: no sabríamos el vector de entrada del ataque (salvo algunos rastros en los logs de navegación del correo).
Sin embargo, hay que romper con esa creencia que tienen muchos defensores en la que “los atacantes son siempre buenísimos, tienen 0-days para dar y regalar, malware invisible y siempre van dos pasos por delante de nosotros”. En muchos casos los atacantes son gente con un nivel técnico similar al de los defensores, con sus herramientas, conocimiento, objetivos y necesidades. Como el autor leyó hace tiempo en Twitter, “los atacantes también tienen jefes y presupuestos”). En definitiva, tenemos que hacer nuestro este mantra:
“Los atacantes no son perfectos”
Esta afirmación implica que a veces serán torpes, cometerán errores o harán algo que nos permitirá detectarlos. Se dice en seguridad que “los defensores tienen que tapar todos los agujeros, mientras que los atacantes únicamente necesitan encontrar uno”. En respuesta ante incidentes, el dicho se invierte: “los atacantes tienen que hacerlo todo perfecto, porque con que cometan un único error podemos detectarlos”.
Muy buenas tardes a todos,
Os remito este comentario MUY interesante de Fernando Rubio, Senior Premier Field Engineer de Microsoft, con el que he estado hablando en el canal de telegram de DFIR (https://t.me/forense):
—
Mi feedback. Estas medidas no son suficientes, y si un atacante ha tomado control de los DCs recuperar este control debe ser planificado convenientemente y lleva meses.
Por ejemplo, no has reseteado las contraseñas de las cuentas de máquina por lo que se pueden hacer silver tickets, ni reinstalado todos los DCs por lo que pueden haberse añadido ASEPs en ellos . Además de otros muchos tipos de persistencia (acls, hidden users, schema, gpos maliciosas…) además los atacantes tiene acceso a la dpapi máster key, que no se puede cambiar…Por otra parte los atacantes, al saberse detectados suelen pasar a modo inactivo durante meses, por lo que esas dos semanas de monitorizacion se quedan cortas.
En resumen, si se llega a esta situación, tienes un problemon entre manos, que no se arregla con dos comandos, y que posiblemente pase por montar un bosque nuevo e ir reinstalando sistemas (con medidas para que no sea infectado nuevamente)
Siento ser puntilloso, pero justo has tocado mi especialidad 😊
Extra:
Por cierto, y por completar… Para recuperar un AD, suponiendo que lo de pegarle fuego no cuele, es importante identificar que sistemas son equivalentes a tier-0, más info aqui:
aka.ms/privsec
porque los backdoor aparte de lógicos en el mismo AD (que hay unos cuantos, como los que detectaba AD time-line del otro dia, o los que se pueden ver con bloodhound) pueden estar en una dependencia del AD, por ejemplo compromiso del vmware habiendo DCs virtuales, de bosques con sid-history habilitado, de sistemas de gestión de los DC con capacidad de ejecutar código arbitrario en los agentes (sccm, monitorizacion, Av, recopilado de logs…), passwords de ILO, y muchos puntos suspensivos…
—
Octan Octancio tiene más razón que un santo: desde un punto de vista técnico la única solución para estar 100% seguros de que hemos erradicado completamente a los atacantes sería “quemar” el bosque de directorio activo (con permiso de ICONA, claro) y “plantar” uno nuevo.
Pero también hay que tener en cuenta que esta operación tiene un coste elevado tanto económicamente (probablemente sería necesario contar con técnicos especializados) como de negocio (habría que hacerlo MUY bien para que no se rompiera nada).
Al final termina siendo una evaluación del riesgo en función de diversos factores: gravedad del incidente, tiempo de compromiso efectivo, habilidad percibida de los atacantes, porcentaje estimado conocido de las actividad de los atacantes … a lo que tenemos que sumar factores de negocio como el valor de la información de la organización y (por desgracia) los recursos disponibles.
Muchas gracias por el comentario altamente enriquecedor, Fernando :)
Un saludo,
Antonio Sanz