En un post anterior Ximo nos habló de los análisis forenses de memoria RAM en Linux y dentro de esta entrada hizo mención a dos herramientas para el análisis de memoria RAM en entornos Windows, que son Mandiant Memoryze y Mandiant AuditViewer.
En esta entrada vamos a ver funcionalidades de la herramienta para conocerla un poco y que sirva como presentación para los que no la conocen. Las pruebas para esta entrada las hemos hecho sobre los ficheros de memoria del reto DFRWS 2005 Forensics Challenge. Por si alguien quiere probar la herramienta los ficheros de memoria son memory1 y memory2. Para profundizar os aconsejamos la guía de usuario que ofrecen los autores y donde están todas las opciones detalladas.
Con todo listo pasamos a cargar el fichero “memory1” en la herramienta AuditViewer, con el wizard de la herramienta. Resumiendo la configuración para la carga del fichero y su análisis, marcaríamos todo menos la adquisición de procesos y drivers; además, para este caso concreto recopilamos la información de todos los procesos. Hay que tener en cuenta que en este caso el fichero de memoria RAM es de 128 MB, por lo que da más pie a marcar todas las opciones y en un corto periodo de tiempo obtener los resultados. En el caso de tener un fichero de memoria más grande, el tiempo de análisis por parte de la herramienta será más largo, ¿obvio no? :), viéndonos obligados a ser más finos en la configuración, sobretodo si no contamos con mucho tiempo. Añadir que esta entrada no intenta resolver el reto, sino que únicamente usa esas imágenes para mostrar funcionalidades de la herramienta.
Una vez cargado el fichero tendremos la siguiente imagen, donde se destaca en color ROJO uno de los procesos que hay en memoria que UMGR32.EXE:
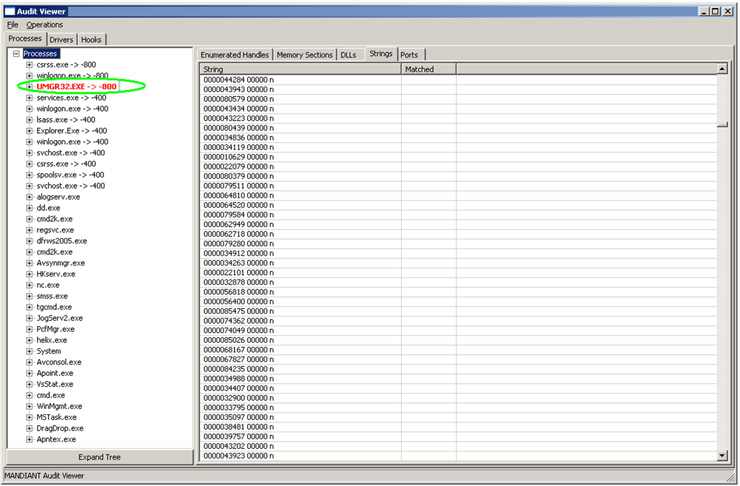
Si miramos la documentación veremos que esto significa que se ha detectado algo sospechoso en ese proceso. Lo primero que nos debemos preguntar nosotros es: ¿Qué es UMGR32.exe? ¿Es un proceso malicioso o es un proceso legítimo y habitual en el sistema operativo? Si realizamos una búsqueda rápida en Google, vemos que todo apunta a que se trata de “Back Orifice 2000”, partiendo del nombre del proceso, dato no determinante.
Con lo que hemos encontrado en Google, decidimos empezar nuestro análisis por este proceso. Es por esto que vamos a ver la información recopilada sobre ese proceso en las diferentes pestañas que nos ofrece la herramienta:

Iremos viendo la información y analizando, intentando encontrar respuestas a las preguntas que pretendemos responder con nuestro análisis. Una de las opciones más interesantes, como suele ser habitual, es Strings, que nos mostrará las cadenas del proceso. En nuestro ejemplo veremos cosas cómo:
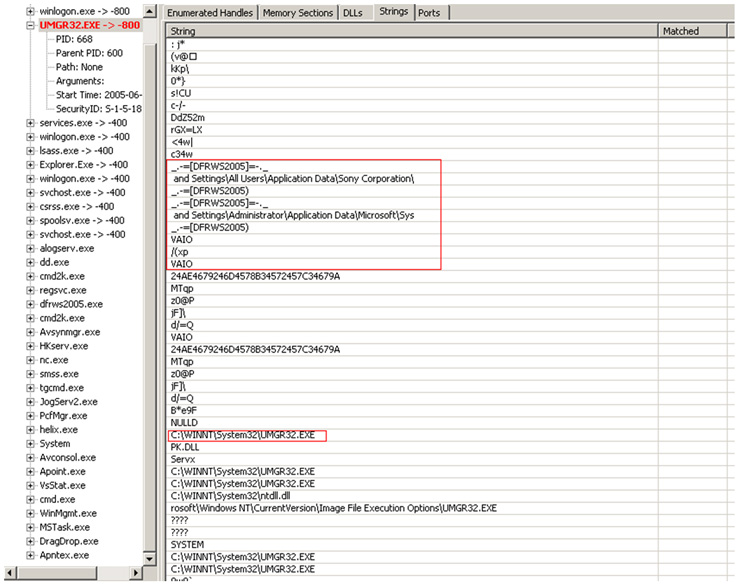
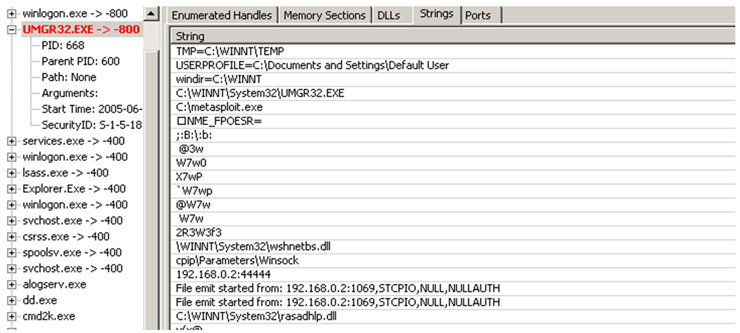
En las imágenes anteriores se ven cadenas bastante sospechosas, como metasploit.exe, como cadena de apertura de sockets en el puerto 44444, etcétera.

Además, si vamos a la pestaña de puertos vemos como tiene a la escucha el proceso el puerto 44444. Hecho que suele ser sospechoso, ¿no? :). Con lo que se requiere analizar en profundidad.

El proceso que ha detectado como sospechoso y por eso lo ha marcado en rojo, es porque tiene código inyectado en memoria y esto requiere un análisis especial. La herramienta de una manera muy visual y sencilla nos ofrece muchas posibilidades para analizar la memoria RAM y generar un informe de manera automática en diferentes formatos. Añadir que la herramienta tiene ciertos mecanismos que ayudan a detectar anomalías, como es el caso de Mandiant Malware Rating Index (MRI), así como la posibilidad de cargar reglas de Snort que transforma en plugins para buscar en la memoria (no he probado esta funcionalidad).
Mi impresión al utilizar la herramienta ha sido buena y os animo a los que no la conozcan a probarla y como siempre a darnos su opinión. Como siempre esperamos que os sea de utilidad.