
Plaso, evolución de la herramienta conocida como log2timeline, es una herramienta desarrollada en Python que permite extraer la línea temporal de todos los eventos ocurridos en un sistema. Admite como como datos de entrada ficheros, discos virtuales, dispositivo de almacenamiento , algún punto de montaje o un volcado de imagen de disco. Como nota aclaratoria aunque la nueva herramienta pasa a denominarse plaso, para ejecutarla se hará a través de “log2timeline.py” lo cual puede llegar a causar confusión.
Plaso nos ofrece un conjunto de herramientas, que de forma resumida son:
- log2timeline: extraer el time line de todos los eventos.
- psort: procesamiento de los datos extraídos.
- pinfo: muestra los datos del fichero de almacenamiento plaso.
- image_export: exporta ficheros de una imagen.
Log2timeline se encarga de analizar los datos recibidos como parámetro de entrada generando un fichero de salida con formato “plaso”, el cual contendrá toda la información de los datos analizados. Dicho fichero de almacenamiento plaso contendrá información como:
- Cuando se ejecutó la herramienta.
- Metadatos de los ficheros analizados de los datos de entrada.
- La información parseada.
- Número de eventos extraídos de los datos de entrada.
Para las pruebas realizadas he optado por usar una imagen de prueba en formato EnCase (parte1 y parte2), accesible para cualquiera que quiera realizar las pruebas.
Como punto de partida, analizaremos la imagen del disco llamada “4DellLatitudeCPi.E01” con log2timeline y guardaremos el resultado en un fichero llamado “reto2.plaso”.
$ log2timeline.py reto2.plaso 4DellLatitudeCPi.E01
Cuando el proceso finalice, tendremos el resultado en el fichero “reto2.plaso”. La herramienta por línea de comandos de pinfo, nos proporcionará información sobre el contenido del fichero plaso. Ejecutamos el siguiente comando y obtendremos información acerca de la información recopilada (ver ilustración 1).
$ pinfo.py reto2.plaso
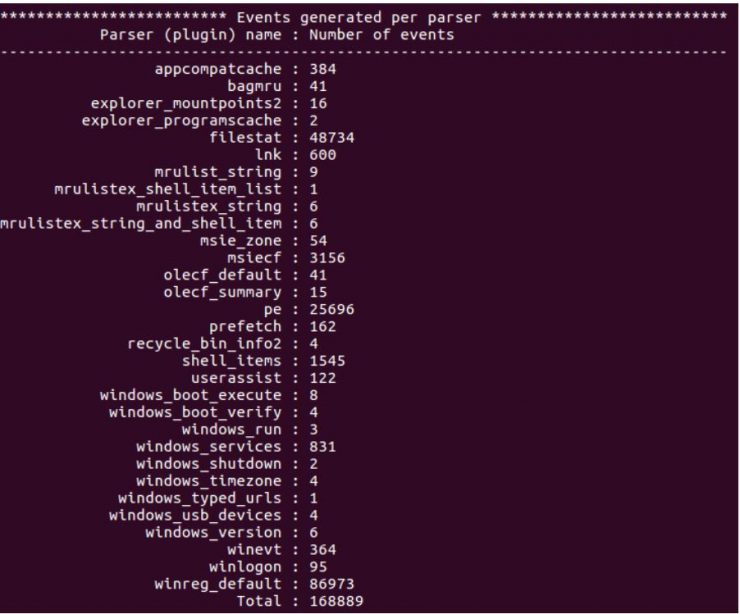
Ilustración 1: Salida de pinfo.py
El resultado nos muestra información de los plugins habilitado, los eventos generados. Por ejemplo, se puede ver que del evento “winevt” (eventos de Windows) ha encontrado 364 eventos. Para extraer dicha información se utilizará psort, la cual es utilizada para el procesamiento de la información contenida en el fichero de plaso, permitiendo filtrar, ordenar y ejecutar análisis automáticos de la información contenida.
A continuación muestro algunos ejemplos de la información que se podría extraer.
1. Extraer toda la información a fichero CSV.
$ psort.py -o l2tcsv -w salida.csv reto2.plaso
2. Extraer toda la información a Elastic.
$ psort.py -o elastic -w salida.csv reto2.plaso
Una vez la información ha sido volcada a un fichero CSV, se pueden realizar búsquedas directamente sobre el fichero para extraer la información. ¿Y, qué buscamos? Pues se puede buscar, por ejemplo, por los tipos de eventos encontrados por log2timeline (ver Ilustración 1). Por ejemplo, se podría extraer las URL escritas por el usuario (“windows_typed_urls”) . Si hacemos una búsqueda en la salida.csv de dicho parser nos mostrará las URL que han sido escritas por el usuario:
$ grep windows_typed_urls salida.csv
Ilustración 2: Búsqueda eventos “windows_typed_urls” (pinchar para ampliar)
Otro ejemplo sería extraer los programas usados por el usuario recientemente, dicha información nos la proporciona la clave del registro MRU (Most Recent Used). En la información que ha mostrado pinfo, se puede ver que hay 9 eventos de MRUlist_string.
$ grep "mrulist_string" salida.csv
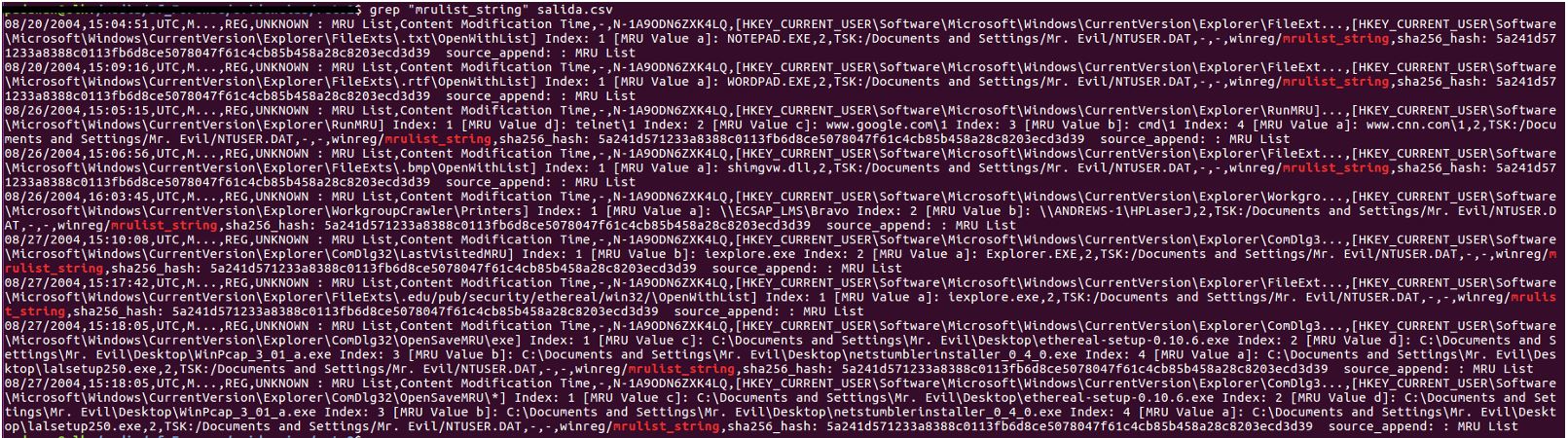
Ilustración 3: Búsqueda eventos “mrulist_string” (pinchar para ampliar)
Además de toda la información extraída, psort permite utilizar unos plugins adicionales para analizar la información. Mostramos en la ilustración 4 un listado de los plugins que se pueden ejecutar.
$ psort.py --analysis list
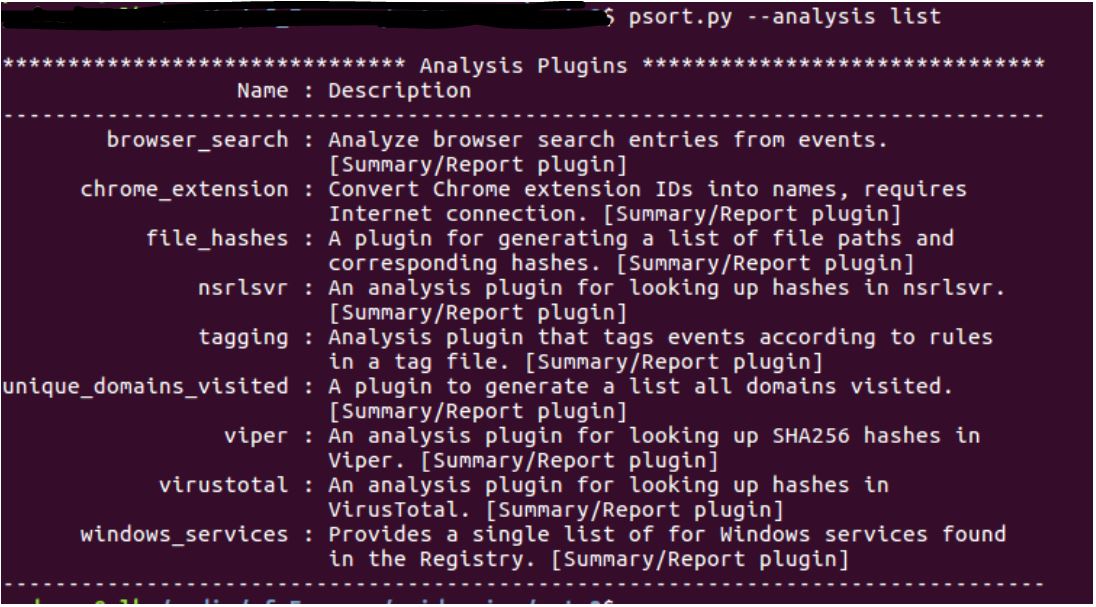
Ilustración 4: Listado de plugins disponibles en psort (pinchar para ampliar)
Utilizando los plugins mostrados en la Ilustración 4, vamos a ejecutar alguno de ellos para extraer información concreta. Utilizaremos como parámetro de entrada el fichero plaso. Por ejemplo:
1. Extraer las búsquedas del navegador utilizado:
$ psort.py –analysis browser_search reto2.plaso
Tras ejecutar el plugin de “browser_search” tenemos dicha información en el fichero “reto2.plaso”. Si se vuelve a ejecutar el comando $ pinfo.py reto2.plaso el resultado sería el siguiente:

Ilustración 5: Resultado ejecución plugin browser_search (pinchar para ampliar)
2. Extraer los dominios únicos visitados:
$psort.py –analysis unique_domains_visited reto2.plaso
Ejecutamos de nuevo $ pinfo reto2.plaso y se obtiene el siguiente resultado de los dominios únicos visitados:

Ilustración 6: Resultado ejecución plugin unique_domains_visited (pinchar para ampliar)
Finalmente, con los resultados obtenidos tras el análisis, se pueden realizar búsquedas sobre el fichero CSV el cual contiene toda la información del parseo del timeline. Por ejemplo, si se sospecha del dominio único visitado “sj9.ru” podríamos hacer un grep en el CSV y obtener el timeline de las visitas a dicho dominio.
$ grep "srj9.ru" salida.csv

Ilustración 7: Búsqueda del dominio sospechoso “sj9.ru” (pinchar para ampliar)
Hasta aquí la funcionalidad básica de plaso, una alternativa a tener en cuenta para extraer el timeline cuando se realiza un análisis forense.