
El ransomware ha venido para quedarse. Eso es algo que está quedando claro. Se trata de un negocio muy lucrativo a tenor del éxito en la tasa de efectividad en la infección, y aunque menor, en la tasa de pagos del rescate por parte de los afectados.
A los ya infames Cryptolocker, CryptoWall, TorrentLocker, TeslaCrypt y demás, se han sumado recientemente HydraCrypt y UmbreCrypt, todos con ligeras variaciones sobre el anterior en un intento de evitar las escasas barreras que están introduciendo las casas de antivirus, junto con alguna iniciativa más o menos ocurrente, y más o menos efectiva, para identificar la actividad de este tipo de amenaza.
Recientemente, el CNI, a través del CCN-CERT, publicó una guía sobre el ransomware en el que se recogían algunas de las variantes junto con herramientas de descifrado de los archivos que han ido proporcionando las diferentes casas de antivirus tras la desarticulación de alguna red de criminales o tras un análisis profundo de las muestras.



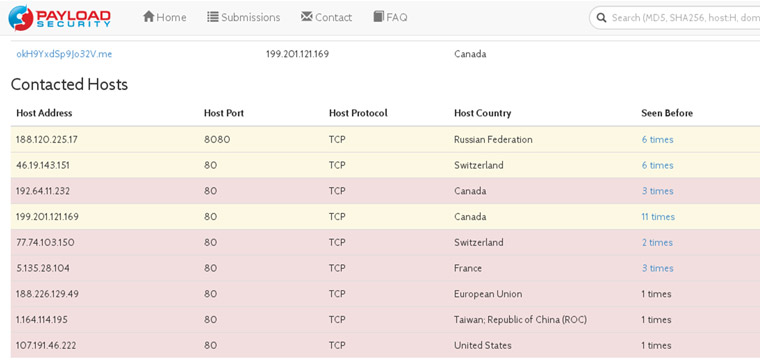
 En Seguridad se utiliza habitualmente el símil de la cadena y el eslabón más débil; ese que dice que la fortaleza de una cadena reside en el eslabón más débil, de forma que por mucha seguridad que se implante en algunos de los sistemas de la infraestructura, todo se puede venir abajo si en algún sistema no se tiene la precaución de seguir las mínimas medidas de seguridad. Resulta que aquel sistema que se encuentra olvidado o se cree que no es importante y en el que no se cumple con las mismas políticas de seguridad puede convertirse en la puerta de entrada para un atacante a toda vuestra infraestructura.
En Seguridad se utiliza habitualmente el símil de la cadena y el eslabón más débil; ese que dice que la fortaleza de una cadena reside en el eslabón más débil, de forma que por mucha seguridad que se implante en algunos de los sistemas de la infraestructura, todo se puede venir abajo si en algún sistema no se tiene la precaución de seguir las mínimas medidas de seguridad. Resulta que aquel sistema que se encuentra olvidado o se cree que no es importante y en el que no se cumple con las mismas políticas de seguridad puede convertirse en la puerta de entrada para un atacante a toda vuestra infraestructura.





















