A principios de septiembre tenía que escribir un artículo para presentarlo como propuesta para la certificación GOLD GCIA de GIAC (SANS). Este documento tenía que estar relacionado con el tráfico de red y la detección de intrusos, orientado al análisis forense.
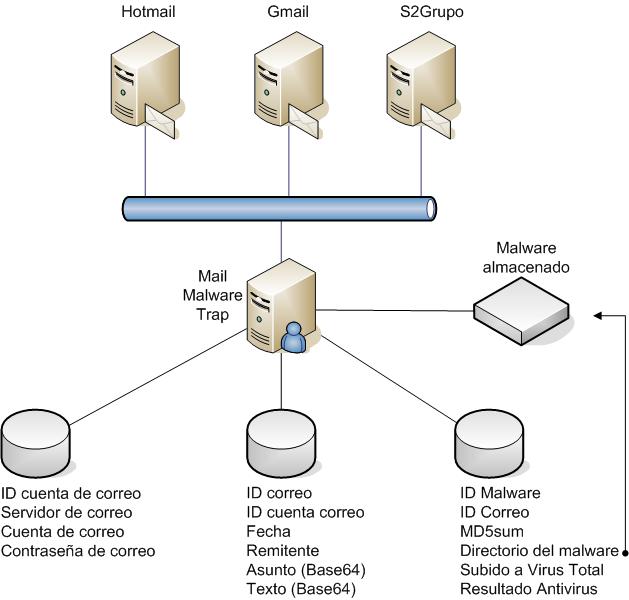
Del conjunto de distintas ideas que tenía en mente, pensé en las veces que me había encontrado con un registro (log) de un servidor Web, en el que se requería emplear expresiones regulares usando listas blancas y negras de patrones que identificasen de entre todas las entradas del registro cuáles podían identificar un incidente de seguridad.
Adicionalmente a las listas negras y blancas, tenemos una serie de herramientas de detección de intrusos a nivel de sistema, donde dado un registro de un servidor es capaz de detectar alertas a partir de unas reglas previamente creadas. Un ejemplo de estas herramientas fue expuesto con anterioridad por José Luis Chica donde se empleó la herramienta OSSEC.
Teniendo en cuenta estos motores de reglas, uno de los entornos con mayor número de reglas son las herramientas de detección de intrusos a nivel de red, como por ejemplo Snort. El principal problema de las herramientas de detección de intrusos a nivel de red es que los datos de entrada requieren justamente eso: tráfico de red, pero el técnico dispone del registro del servidor y no del tráfico de red que lo generó.
Por tanto, para poder usar estos motores de reglas es necesario ser capaz de leer ese registro de entrada y a partir de éste, generar el tráfico de red oportuno, de forma que dicho tráfico de red pueda ser inyectado en una herramienta de detección de intrusos a nivel de red. Con esta idea programé una pequeña herramienta (prueba de concepto), la cual es capaz de leer el fichero de registro de un ISS, Apache, Nginx o IBM Web Seal y guardar en un fichero PCAP el tráfico de red que generó dicho registro.
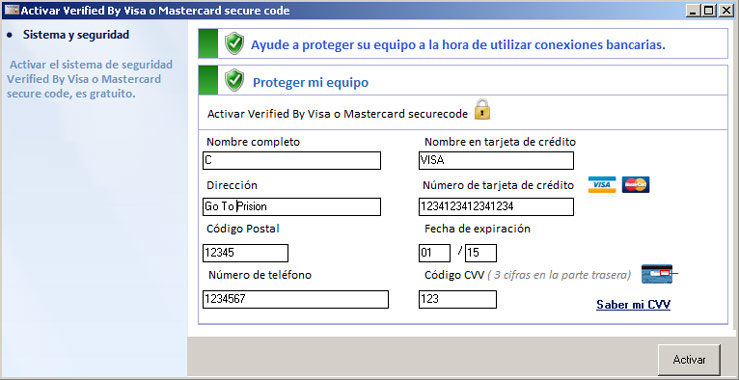
Para entenderlo mejor vamos a ver un ejemplo de uso de la herramienta, donde se dispone de un registro de un servidor web Apache donde una IP atacante (y ficticia) ha realizado una auditoría Web con la herramienta Nikto:

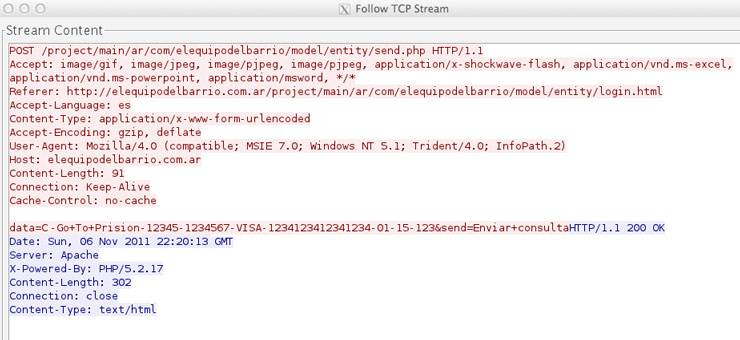
Por ello vamos a proceder a usar la herramienta Log2Pcap para que recree el tráfico de red correspondiente al registro del servidor. Lo primero es indicar donde está el fichero del registro, que se trata de un servidor Apache, la IP y puerto del servidor Web que ha sido auditado:

Como resultado tenemos un fichero llamado “result.pcap” que ocupa 168 K. Dicho fichero ya puede ser leído por todas las herramientas de red que tengan la capacidad de leer el fichero PCAP, como por ejemplo Tcpdump o Tcpflow:

De la misma forma que puede ser inyectado en este tipo de herramientas, también puede ser inyectado en un Snort para que emplee el motor de reglas en búsqueda de posibles ataques:

Dando como resultado las siguientes alertas:

El código fuente de la herramienta lo podéis encontrar aquí mientras que la documentación la tenéis explicada aquí. Siento que el inglés no sea el mejor pero el documento fue escrito hace aproximadamente cinco meses.
Respecto a la evolución de la herramienta, la segunda versión está casi terminada. La herramienta ha sido prácticamente reescrita desde cero y se han añadido funcionalidades como poder inyectar el tráfico a un interfaz de red sin ser necesaria la creación del fichero PCAP, API orientada a objetos e integración con Plaso.
En lo concerniente a las limitaciones la más importante es obvia: se depende totalmente de la integridad y de la información almacenada en dicho registro. Durante el desarrollo de la herramienta caí en la cuenta que prácticamente la mayoría de servidores web no registran por defecto las variables enviadas por POST. Por lo tanto, aunque la herramienta está preparada para leer registros con parámetros POST, si el servidor no está configurado adecuadamente se está perdiendo mucha información. La segunda limitación viene dada al intentar establecer una línea de tiempo, puesto que en ningún momento la herramienta relaciona la alerta de Snort con la entrada del registro que generó la alerta.
Otro punto importante a entender es que la herramienta no pretende sustituir a las expresiones regulares, a los motores de detección de intrusos a nivel de host o cualquier otro método usado previamente. El objetivo de la herramienta es ofrecer otra opción más que pueda proporcionar más información al técnico que gestione el incidente.
Para evitar confusión quiero comentar que existe otra herramienta perteneciente al motor de Samba que usa el mismo nombre. La cual hace justamente lo que su nombre indica: coge un fichero samba y genera un fichero PCAP. He de reconocer que nunca he usado dicha herramienta y que no conocía la existencia de la misma. Ambas tienen propósitos totalmente distintos, protocolos distintos y nada en común. He mantenido el nombre Log2Pcap porque es la metodología de nombre empleado para este tipo de herramienta. Posiblemente en la segunda versión, y dada las nuevas funcionalidades, le cambiaré el nombre a LogWeb2Net.
Para finalizar agradecería que los lectores me enviasen el fichero log de cualquier otro servidor Web no soportado hasta la fecha, lógicamente anonimizado antes del envío. Con un par de líneas donde se traten diferentes métodos como GET y POST sería suficiente.