
Desde el punto de vista del Threat Hunting, uno de los grandes retos siempre es el modelaje de aquellas anomalías que podemos percibir a simple vista y la generación de reglas que poder integrar en nuestras herramientas.
Para la siguiente serie de artículos se va a dar una aproximación léxica, analizando nuestro lenguaje y su implementación en el entorno TI para la extracción de diferentes anomalías basadas en la ortografía del castellano.
Durante el siguiente artículo vamos a extraer un algoritmo que nos permita la detección de esos dominios generados con DGA a través de la ponderación de cada uno de los caracteres latinos.
El primer paso del análisis va a ser la extracción de las letras más usadas en los nombres de dominio. Para ello, nos hemos descargado millón de dominios más visitados en Internet (http://downloads.majestic.com/majestic_million[.]csv) de cara a obtener el número de veces que aparece cada letra.
El resultado extraído es el siguiente:
{'1': 28757, '0': 23576, '3': 16525, '2': 24528, '5': 14664, '4': 14799, '7': 11530, '6': 13227, '9': 12589, '8': 16927, ':': 1, 'D': 1, 'a': 1001482, 'c': 1080492, 'b': 250047, 'e': 1123076, 'd': 367221, 'g': 371755, 'f': 194018, 'i': 811689, 'h': 310991, 'k': 214124, 'j': 89838, 'm': 882613, 'l': 536198, 'o': 1416894, 'n': 804749, 'q': 29133, 'p': 317901, 's': 704411, 'r': 830929, 'u': 435880, 't': 715609, 'w': 149759, 'v': 155356, 'y': 194915, 'x': 75099, 'z': 92003}
Teniendo en cuenta que la muestra utilizada es de un millón, se decide asignar un valor a cada letra según su porcentaje de aparición en los diferentes dominios: 10 al percentil 10, 9 al percentil 20, 8 al percentil 30…
La letra menos utilizada es ‘q’ que aparece 29.000 veces, siendo poco más del 2,5% de la muestra, seguido de la letra ‘x’ con 75.000, con un 7,5%.
En cuanto a las letras más relevantes, tenemos la ‘o’ con la presencia en más del 83% de los dominios, seguido por la ‘c’ y ‘a’, con el 75% y el 62%, respectivamente.
El análisis numérico supone un reto. No es tan habitual que aparezca en un dominio, sin embargo el mero hecho de estar no supone una anomalía de igual grado que una letra con las mismas apariciones. Podemos observar que el número 7 es el que menos apariciones tiene en la lista, sin embargo, vamos a tomar otro valor al respecto, su posición en la palabra.
Suele ser bastante habitual que los números aparezcan al final del dominio, pocas veces intercalados por letras, por lo que, siempre que después de su posición no existan letras, vamos a ponderarlos con uno de los tres valores 3, 6 y 9.
Hasta aquí el análisis generalista. Sin embargo, igual de importante que la capacidad de detección de amenazas es el conocimiento de nuestro entorno, así pues, para dotarle de una mayor contextualidad , vamos a incorporar a nuestro análisis un estudio sobre el castellano.
En este caso vamos a extraer información de la obra más importante de nuestra lengua: El Quijote. A través de los conceptos ortográficos de dígrafo y trígrafo, que no es más que la combinación de dos y tres letras, respectivamente.
Si extraemos todas las palabras contenidas en el Quijote y lanzamos contra éstas todas las combinaciones de dígrafos, encontramos que, de 676 posibles combinaciones de dos letras, 357 no están presentes.
En cuanto a los trígrafos, tenemos un total de 15.081 combinaciones no presentes en el texto, por un total de 17.576 combinaciones posibles.
Toda esta información la vamos a incorporar a nuestro algoritmo a través de la suma adicional de 10 en todas aquellas combinaciones no existentes en el castellano.
Implementando esta versión alpha del algoritmo sobre la muestra del millón de dominios, nos encontramos con los siguientes resultados:
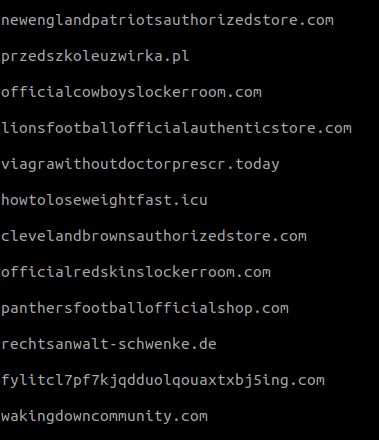
A pesar de que tenemos un caso de éxito con el dominio fylitcl7pf7kjqdduolqouaxtxbj5ing[.]com, nos topamos con un gran número de falsos positivos, primero por la longitud del dominio y, segundo, por inferencia del idioma inglés.
Para el primero de los problemas debemos tener en cuenta una ponderación que compense la longitud, por ello vamos a calcular el número de letras y multiplicar por el valor medio de letra, es decir, 5. Este valor será restado al valor total de la palabra.
En cuanto al tema del inglés, se va a realizar el mismo estudio de dígrafos y trígrafos, esta vez sobre la obra más larga (y una de las más influyentes) de Shakespeare: Hamlet.
Una vez tenemos este nuevo listado excepcionamos de la primera de las listas los dígrafos y trígrafos encontrados en esta segunda parte del análisis.
El pseudocódigo del algoritmo planteado sería el siguiente:
for letra in dominio: valorDominio = valorPalabra + valorLetra[letra] for digrafo in listaDigrafosNoExistentes: if digrafo in dominio: valorDominio = valorDominio + 10 for trigrafo in listaTrigrafosNoExistentes: valorDominio = valorDominio + 10 valorDominio = valorDominio - len(dominio)*5
Ejecutando de nuevo la implementación del algoritmo sobre el pull de dominios, obtenemos el siguiente resultado:
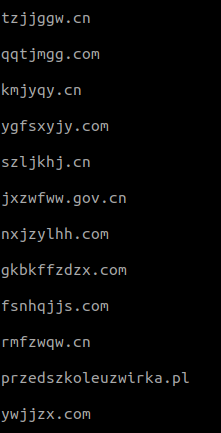
Tal y como podemos observar, los resultados se acercan con gran exactitud a los esperados, si bien es cierto que encontramos falsos positivos con el lenguaje polaco y la transcripción del pinyin al alfabeto latino.
Así pues, ya tenemos un sencillo algoritmo que nos permite la detección de esos dominios no legíbles y posiblemente generados de manera aleatoria, tal y como podría llevar a cabo un malware de carácter genérico.
El código de dicho algoritmo se puede encontrar en el Github de Security Art Work (https://github.com/SecurityArtWork/ortTH).
Hasta aquí el análisis de aquellos dominios sospechosos a simple vista, sin embargo, ¿es posible que un algoritmo nos alerte de anomalías en dominios no perceptibles a simple vista?