
A la hora de utilizar un dominio para la comunicación con el servidor de mando y control y/o de exfiltración, los grupos de mayor sofisticación suelen utilizar nombres que pasan desapercibidos en un primer vistazo (e incluso hasta después de varios) por los analistas.
La utilización de palabras del ámbito tecnológico o relacionadas con el sector de la organización suelen proporcionar una capa adicional de ocultación en las ya de por sí discretas comunicaciones. Sin embargo, ¿podemos detectar estos dominios?
El objetivo del siguiente artículo es buscar patrones entre los IoC de diferentes APT y compararlos con el listado del millón de dominios más utilizados que proporciona Alexa, de cara a generar un algoritmo que permita ponderar la probabilidad de que un dominio intente hacerse pasar por legítimo.
En un primer análisis, lo que llama la atención es la gran cantidad de dominios con guiones.
En los dominios utilizados, casi el 50% de los dominios contienen un guión. Si comparamos estos datos con el millón de dominios más visitados por Alexa, encontramos que sólo el 10% de los dominios contienen guiones. Esta presencia de guiones es un factor a tener en cuenta.
A continuación, lanzamos el diccionario inglés sobre todos los dominios, con objeto de detectar aquellas palabras de uso común que más veces aparecen sobre los dominios maliciosos. Del análisis se obtienen las siguientes palabras:
| update | |
| news | date |
| login | support |
| service | account |
| down | cloud |
| security | books |
| check | client |
| media | music |
| press | secure |
| help | main |
El siguiente paso es monitorizar la suplantación, pues también se ha detectado un gran número de dominios que intentan la suplantación de servicios de corte generalista, como puede ser Gmail, Microsoft, Facebook, etc.
| gmail | microsoft | windows | apple | |
| office | outlook | itunes | kaspersky | iphone |
| android | firefox | yahoo | mcafee | azure |
| hotmail | akamai | zoom | asus |
Además, añadiremos “Msn” y “365” sin condicionantes. También podríamos añadir “live”, dado que es utilizado por servicios de Microsoft. Sin embargo, el número de falsos positivos que genera no permite ponderarlo de la misma manera que otro, por lo que será incluido como palabra de uso común.
En cuanto la detección de suplantaciones de servicios generalistas, se podría optar por diferentes aproximaciones, como pudiera ser la distancia Leveshtein. En este caso la aproximación es la siguiente:
- Para que asimilemos un conjunto de letras a otro debe compartir un número mínimo de caracteres. Es decir, goCloud.com no permite asociarlo a Google, sin embargo googlCloud[.]com sí. Se ha considerado que este conjunto de letras son las siguientes:
| Goog, ogle | |
| Apple | Appl, pple |
| Amazon | Amaz, mazon |
| Office | Off, ffice |
| Outlook | Outl |
| Itunes | Tunes, itun |
| Gmail | Gma |
| Kaspersky | Kasp, spersk, rsky |
| Iphone | Iph, phon, phone |
| Android | Andr, ndron droi |
| Firefox | Firef, irefo, refox |
| Yahoo | Yah, ahoo |
| Mcafee | mcaf, cafee |
| Azure | azur, zure |
| Hotmail | Hotm, otmai, tmail |
| Akamai | Akam, kamai |
- Existen letras y números que se asemejan y que pueden utilizarse sustituyéndose entre ellas, se ha considerado que algunas son las siguientes:
i/l/1 – s5 – e3 – gq6 – a4 – o0 – t7 – mn – wvu –
- La repetición de alguno de los caracteres es habitual en el intento de suplantación, como por ejemplo, gooogle[.]com. En este caso se han realizado expresiones regulares para matchear estas combinaciones del siguiente tipo:
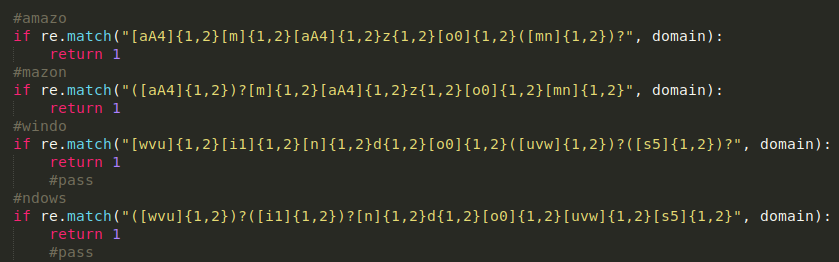
- También se ha añadido una verificación adicional para que, en el caso de que haga match con la expresión regular y no contenga la palabra del servicio en sí, sea considerado como suplantación.
- Por otro lado, vamos a tomar el TLD como valor adicional para la ponderación. Dado que estas empresas suelen tener páginas prácticamente en todos los idiomas existentes, le vamos a restar valor de dominio si su TLD es .com, .net, .org o cualquiera de los siguientes: .br, .de, .nu, .uk, .cn, .pe, .it, .fr, .nl, .mx, .jp
- Se considera que una palabra de uso común por sí sola no es suficiente para clasificarla como sospechosa. Tampoco si su TLD no es habitual y/o tiene un guión y dependerá de la reiteración de éstas o de su combinación con palabras de servicios públicos.
- Las palabras de servicios públicos suelen estar relacionados con servicios legítimos, así pues se necesitará cualquiera del resto de parámetros para llegar a 100.
- Debido a que existen dominios que utilizan los guiones como recurso para separar palabras de una frase, se ha puesto un límite de 60, siendo necesaria además de la existencia de otro de los factor para que llegue a 100.
Una vez mostrados los detalles del análisis, se ponderará cada uno de los factores para que el valor para clasificar a un dominio como malicioso sea 100. Resumiendo lo visto, se han asignado los siguientes valores:
- Palabras de uso común → 50
- TLD → 40
- Guiones → 30
- palabras de servicios públicos → 90
- palabras de servicios públicos suplantadas → 120
Si chequeamos sobre un listado de dominios de carácter genérico, encontramos matches como los siguientes:
- 4maz0n[.]com
- account1-update[.]com
- facebook-login[.]club
- instagram-support-coronavirus[.]net
- microsoft365[.]systems
- outlook-pst-recovery[.]com
- windowrepairsmontreal[.]com
Tal y como podemos ver, detectadmos el tipo de dominios potencialmente maliciosos que son el objetivo del algoritmo.
En cuanto a la aplicación del algoritmo en producción, se tienen que tener en cuenta los siguientes factores:
- Existe la inherente detección de falsos positivos, que deberá solventarse con la utilización y actualización de listas blancas.
- Es recomendable adaptar las palabras de uso común al contexto de la organización a monitorizar, incluyendo, por ejemplo, palabras como energy, goverment o aero según su ámbito de actuación para ponderarlas de manera superior a las genéricas.
- Se recomienda particularizar el estudio a cada uno de los actores de cara a detectar procedimientos particulares de cada uno de ellos y que en un análisis global hayan podido pasar desapercibidos.
Una implementación del algoritmo en Python puede ser encontrada en el Github de Lab52.