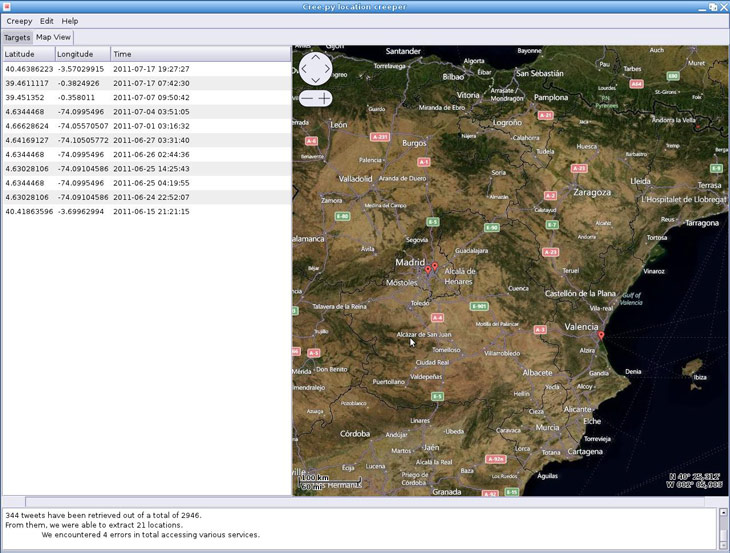
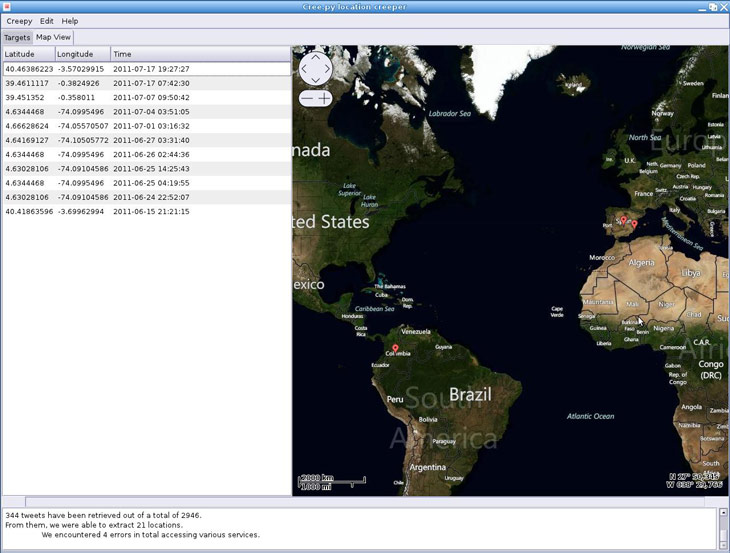
Ossec es un conocido HIDS que además de controlar modificaciones de ficheros, analiza logs de las máquinas monitorizadas en busca de algún evento que pueda ser signo de un ataque. Reconoce y parsea gran cantidad de tipos de logs y tiene un motor de reglas con capacidad de correlación. Esta es su funcionalidad habitual, aunque también puede ser realmente útil como herramienta para la investigación de un incidente. Ossec tiene una herramienta que aunque originalmente sirve como diagnóstico del correcto funcionamiento de la aplicación, puede procesar un log recopilado offline de un equipo no monitorizado inicialmente, y procesarlo en el motor de ossec con el fin de encontrar evidencias de forma muy sencilla.
Pongamos como ejemplo, una máquina de la que se sospecha que ha podido verse comprometida. No tiene ningún HIDS instalado, ni su infraestructura dispone de un NIDS. Tan solo se tiene a salvo los logs del sistema, que se han almacenado en un servidor de syslog remoto, a salvo de alteraciones del presunto intruso.
El pobre incident handler se encuentra con que las únicas evidencias que le han facilitado para investigar son unos logs del sistema de varios cientos de MB. A pesar de que la forma más precisa de escarbar entre tanto log suele ser abrirlo con un editor, como highlighter, y comenzar a buscar cadenas, se puede automatizar la tarea procesando los logs con ossec, y tener una idea inicial de que ha ocurrido.
# cat auth.log | /var/ossec/ossec-logtest -a
Unos instantes más tarde nos muestra las alertas detectadas. Ossec clasifica alertas con un nivel por su grado de criticidad, de0 a16. Se puede echar un vistazo a los resultados y buscar alertas con level alto. En el caso del ejemplo encontramos esto:
** Alert 1359192816.27: mail - syslog,attacks, 2013 Jan 26 10:33:36 hostVictima->stdin Rule: 40112 (level 12) -> 'Multiple authentication failures followed by a success.' Src IP: 172.16.1.99 User: root Jan 26 05:28:28 hostVictima sshd[20423]: Accepted password for root from 172.16.1.99 port 60876 ssh2
Se puede ver claramente que han hecho un ataque de fuerza bruta contra el servicio ssh y que el ataque ha resultado efectivo.
Veamos otro ejemplo, esta vez con un log de apache:
# cat vhost1.access.log | /var/ossec/ossec-logtest -a
En este caso el resultado es un log bastante extenso, de bastantes KB, con alertas de mayor y menor criticidad, y encontrar algo interesante puede llevar algo de tiempo. En este caso se puede utilizar la herramienta ossec-reportd, que muestra un resumen estadístico de las reglas que ha procesado:
# cat vhost1.access.log | /var/ossec/ossec-logtest -a | /var/ossec/ossec-reportd Top entries for 'Source ip': ------------------------------------------------ 10.10.10.4 |10 | 172.16.1.99 |6 | Top entries for 'Level': ------------------------------------------------ Severity 10 |5 | Severity 6 |11 | Top entries for 'Rule': ------------------------------------------------ 31151 - Multiple web server 400 error codes |11 | 31502 - TimThumb vulnerability exploit attempt |4 | 31510 - WordPress wp-login.php brute force attack |1 |
Se descubre por tanto que por los errores 400 probablemente haya habido un intento de descubrimiento de directorios, varios intentos de explotar una vulnerabilidad en el plugin TimThumb, y un ataque de fuerza bruta al login del wordpress.
Se pueden analizar muchos más tipos de logs. La versión actual de ossec incorpora 62 rulesets, por lo que abarca una gran variedad de aplicaciones y dispositivos.
 El uso del sistema operativo Android está creciendo a una velocidad que asusta.
El uso del sistema operativo Android está creciendo a una velocidad que asusta. 

 Una de las tareas comunes que deben aplicarse a un servidor que va a pasar a producción es fortalecer la seguridad que lleva por defecto el sistema. A esto se le llama bastionar o securizar. Como son muchos aspectos los que hay que tener en cuenta para llevar a cabo esta labor, he querido hacer un recopilatorio de las principales tareas de bastionado en Linux.
Una de las tareas comunes que deben aplicarse a un servidor que va a pasar a producción es fortalecer la seguridad que lleva por defecto el sistema. A esto se le llama bastionar o securizar. Como son muchos aspectos los que hay que tener en cuenta para llevar a cabo esta labor, he querido hacer un recopilatorio de las principales tareas de bastionado en Linux. 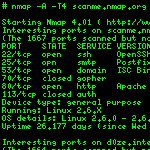 Nmap es una archiconocida herramienta de escaneo de red. Seguramente todos los que estéis leyendo esto la habréis utilizado alguna vez. Permite de forma muy sencilla hacer una enumeración de los equipos que hay conectados a una red, o descubrir los servicios disponibles en una máquina. Cuando hacemos esto de forma ocasional, y para un escaneo de una red pequeña, o para un solo equipo, no nos paramos a pensar en afinar la configuración, y escribimos la ristra de parámetros que nos sabemos de memoria. En mi caso suelo usar:
Nmap es una archiconocida herramienta de escaneo de red. Seguramente todos los que estéis leyendo esto la habréis utilizado alguna vez. Permite de forma muy sencilla hacer una enumeración de los equipos que hay conectados a una red, o descubrir los servicios disponibles en una máquina. Cuando hacemos esto de forma ocasional, y para un escaneo de una red pequeña, o para un solo equipo, no nos paramos a pensar en afinar la configuración, y escribimos la ristra de parámetros que nos sabemos de memoria. En mi caso suelo usar: