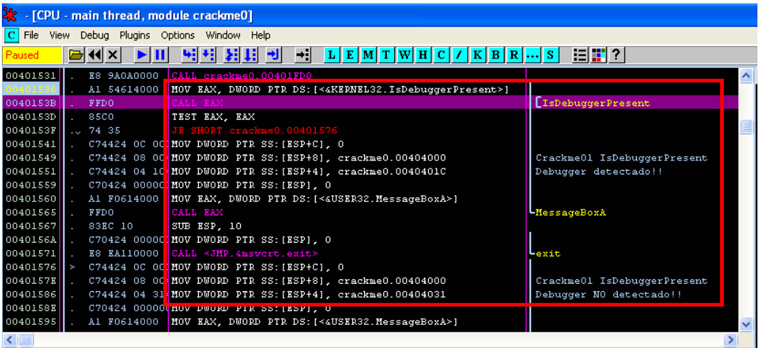
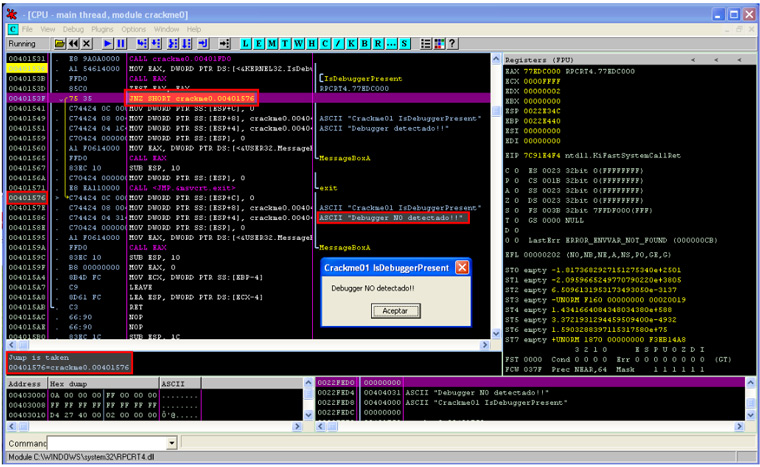
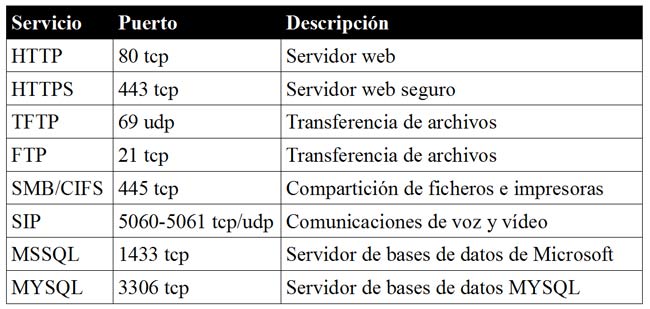
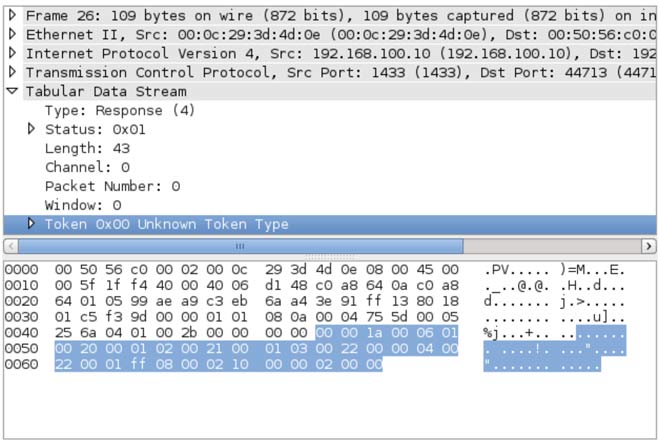
¿Cuántos de nosotros hemos utilizado la red TOR o un proxy anónimo para navegar de forma anónima? Y, ¿cuántos hemos tenido en cuenta que las peticiones DNS que realiza nuestra máquina puede que no sean enrutadas a través de la red TOR? Este simple descuido puede ser usado para identificarnos mediante algún tipo de correlación. Por ejemplo, un usuario que ha hecho consultas DNS de un dominio que posteriormente ha sido atacado a través de TOR. Aunque es complicado llegar a esta situación, puede darse el caso.
Actualmente es posible utilizar el propio cliente de TOR para enrutar las peticiones a través de esta red, u otras herramientas como dnsmasq, que actúa como un proxy capaz de redirigir las peticiones DNS a través de una red determinada. Aun así, las peticiones DNS realizadas no están cifradas, algo totalmente deseable. De esta forma, da igual si las peticiones son capturadas, ya que seguiremos manteniendo el anonimato sobre las consultas realizadas.