
Hace unos meses, nuestro compañero Jose Vila ya nos habló de Logstash como alternativa a Splunk para análisis de logs, poniendo como ejemplo como se podía analizar un conjunto de logs de Apache y contándonos cómo personalizar un dashboard de Kibana para analizar alertas procedentes de Snort [1] [2]. En esta ocasión vamos a continuar hablando de Logstash, poniendo como ejemplo como buscar algunas anomalías en un fichero de log de un proxy de navegación de un Squid.
Lo primero a tener en cuenta sería definir el fichero de configuración que le pasaremos a Logstash para que nos interprete, de la manera adecuada, el log del Squid. Este fichero es el que yo me he definido (se puede descargar del siguiente repositorio: https://github.com/mmorenog/Kibana):
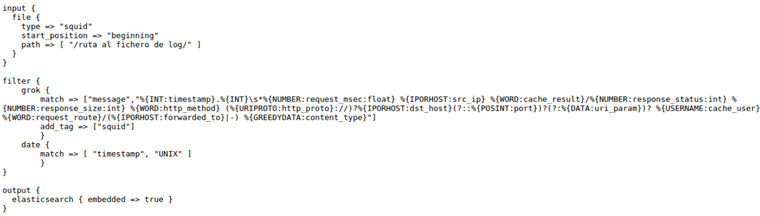
Una vez definido el fichero de configuración podemos cargar en Kibana el fichero de log a analizar:
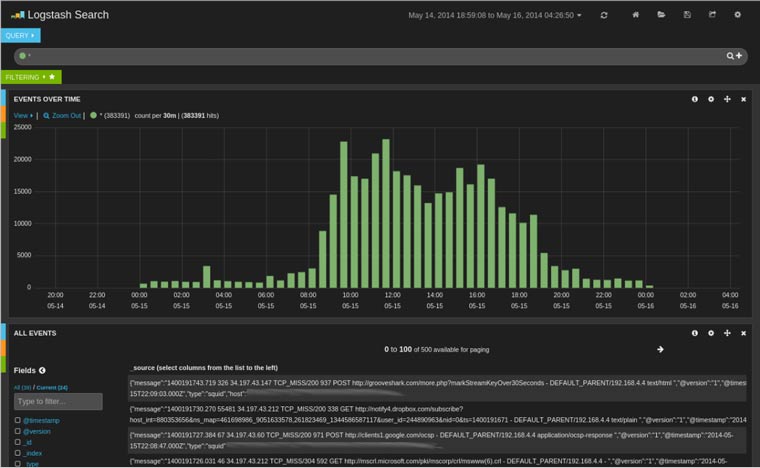
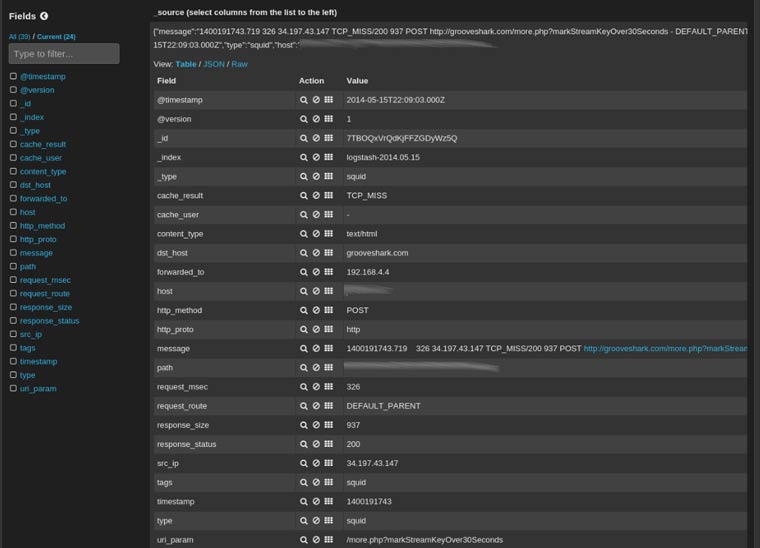
En este dashboard inicial vemos el histograma con todos los eventos del log, seguido de una visualización detallada de cada línea del log interpretada como le hemos indicado en el fichero de configuración que previamente hemos diseñado. A continuación un detalle de una de las líneas:
Para ir perfilando nuestro dashboard de visualización, podemos ir añadiendo paneles con la información que nos interese, como por ejemplo el tamaño medio de las peticiones, el tiempo medio desde que se lleva a cabo una petición y se obtiene respuesta, destinos menos solicitados, content-type más anómalos, etc.
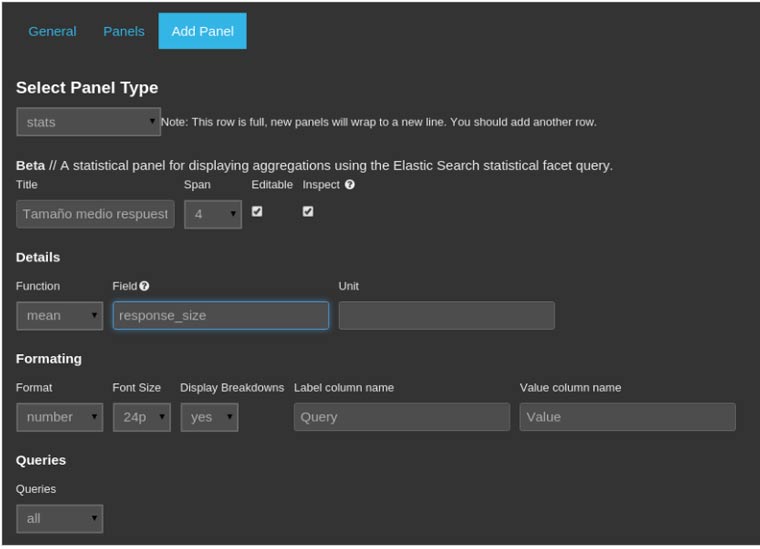
Un ejemplo de como crear un panel para que nos muestre el tamaño medio de las respuestas que seleccionemos en nuestro histograma de eventos, sería el siguiente:
Añadiendo los paneles anteriormente comentados, nuestro dashboard para el log del Squid tendría el siguiente aspecto:
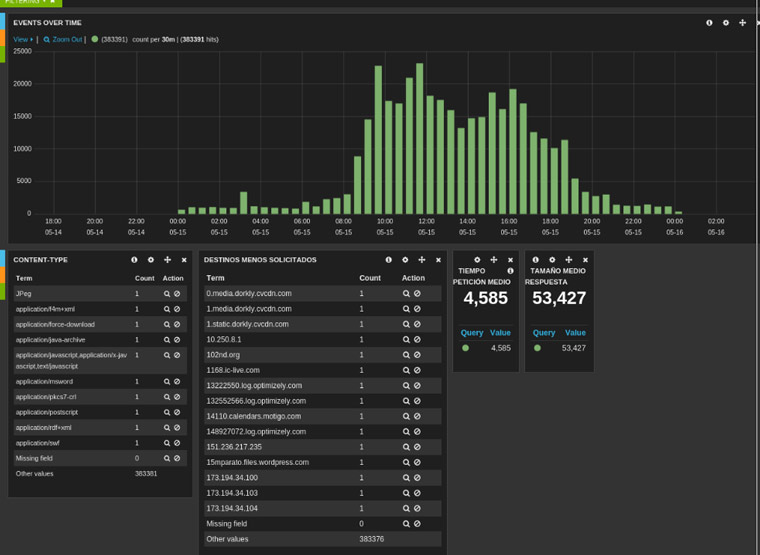
Comentar en este punto, que cualquier búsqueda o filtrado que hagamos sobre nuestro histograma de eventos, afectará a todos los paneles que tenemos en el dashboard, ciñéndose los resultados a la búsqueda/filtrado que se han llevado a cabo. Por ejemplo, si hacemos una búsqueda en una determinada franja horaria de los métodos HTTP más utilizados, nuestro dashboard adoptaría el siguiente aspecto:
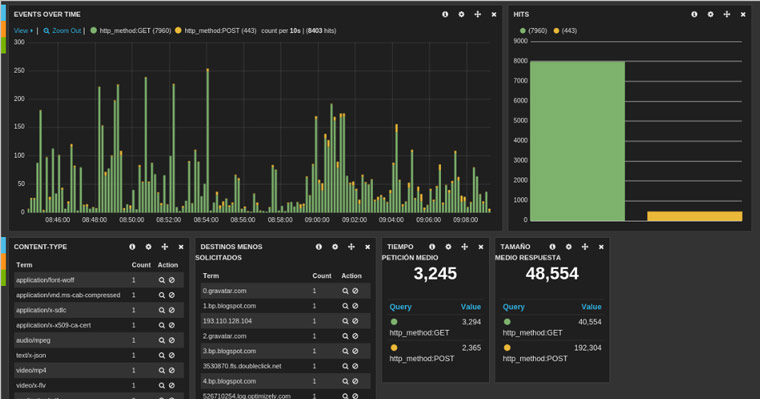
Como se observa, las peticiones pueden quedarse fijas en el histograma diferenciándose por colores. También es posible generar un gráfico de barras con la cuenta total de los resultados de las búsquedas que hemos realizado en el intervalo temporal solicitado, como se muestra a la derecha.
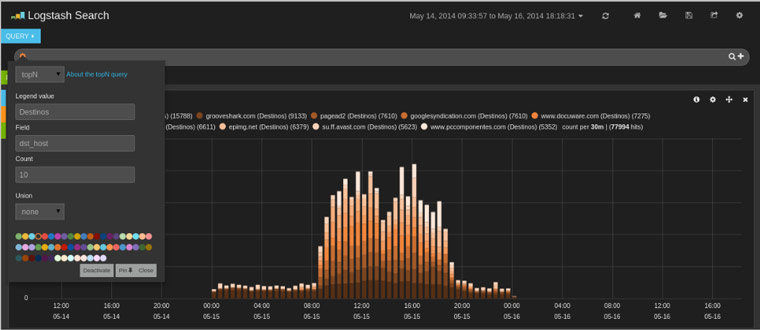
Otra búsqueda que podemos hacer sería la de obtener un Top 10 de los destinos más solicitados dejando fija esta petición del Top 10 en el panel de búsqueda:
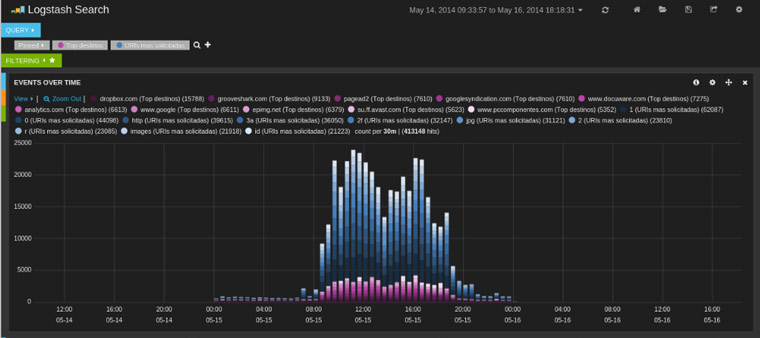
O incluso añadiendo también las URI más solicitadas:
Una vez hemos visto las posibilidades de representación que nos permite Kibana a la hora de diseñar paneles de visualización, comentemos algunas anomalías indicativas de compromiso a tener en cuenta en un proxy de navegación:
- Identificar conexiones a servidores C&C en listas negras (importante mantener actualizadas estas listas).
- Identificar tráfico en horario no laboral (cualquier tráfico de navegación fuera del horario habitual es una anomalía a investigar, sin embargo, la mayoría del malware avanzado respeta el horario no laboral e incluso algunos, los días festivos de la región/país).
- Identificar conexiones periódicas a servidores de C&C (por ejemplo, anómalo sería que un equipo estuviera haciendo conexiones cada día entre las 8:00am y las 10:00am exactamente al mismo destino cada 3 minutos). Igual que antes, si el malware es lo suficientemente sofisticado, programará aleatoriedad en sus conexiones para no caer en ningún tipo de periodicidad que pudiera dar indicios de un patrón identificable.
- Identificación de anomalías estadísticas univariables:
- Dominios menos solicitados.
- Content-Type estadísticamente anómalos.
- etc.
- Identificación de anomalías mediante análisis estadístico multivariable; es decir, campos que no son anómalos por sí mismos, pero cuya combinación si lo es:
- Detección de exfiltraciones satelitales (extremadamente lentas). Por ejemplo conexiones de un tamaño pequeño frente a un tiempo de conexión alto.
- Otro ejemplo podría ser una combinación anómala de Content-Type, código HTTP y tamaño de la transacción.
- Imaginemos detectar un equipo haciendo peticiones a un dominio y que éste devuelva siempre un 404, un tamaño grande y variable, y contenido binario. Como se observa, un campo por sí solo no muestra evidencias de ser algo extraño, sin embargo la combinación de todos lo es; una página que se pide constantemente y no se encuentra, que devuelve un tamaño grande y cambiante, con formato de aplicación…cuanto menos habría que investigar el comportamiento.
Pongamos ahora en práctica con Kibana la búsqueda de algunas de las anomalías citadas.
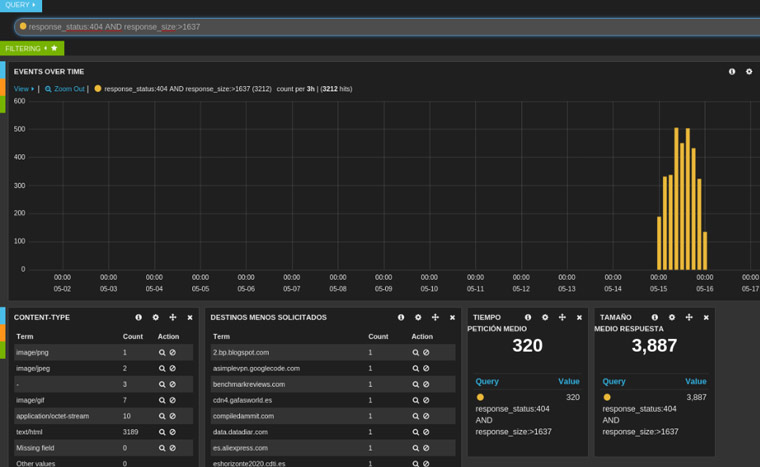
Si nos fijamos en la [Imagen 4], en el panel de los “Content-Type” menos solicitados, nos llama la atención por ejemplo uno denominado “JPeg”, lo cual es un formato inválido, y por tanto anómalo y cuya petición que lo ha generado habría que investigar.
Partiendo de nuevo de la [Imagen 4], vemos que el tiempo de petición medio que tenemos es de 4,585 y el tamaño medio de respuesta es de 53,427. Por tanto, para acotar una zona de eventos en nuestro log que nos pueda mostrar “conexiones lentas”, se podría obtener para una consulta del tipo request_msec:>4585 and request_size:<5327. El resultado podría ser algo susceptible de ser analizado en profundidad.
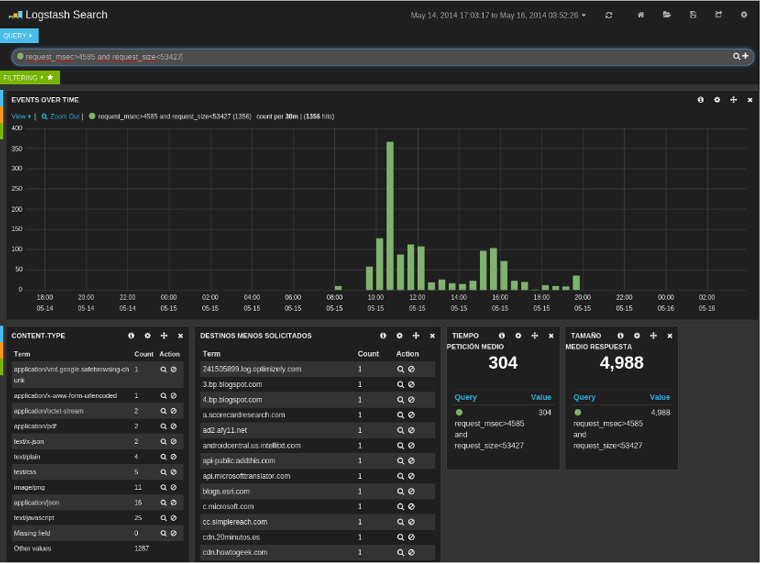
Otra búsqueda interesante que podríamos hacer es la de buscar todos aquellos “gif” (que aparezcan en el uri_param), sin embargo que en el content_type no aparezca el tipo esperado para un “gif”, sino algo que pudiera identificar un ejecutable por ejemplo. Esas peticiones que aparecen en nuestro log deberíamos estudiarlas:
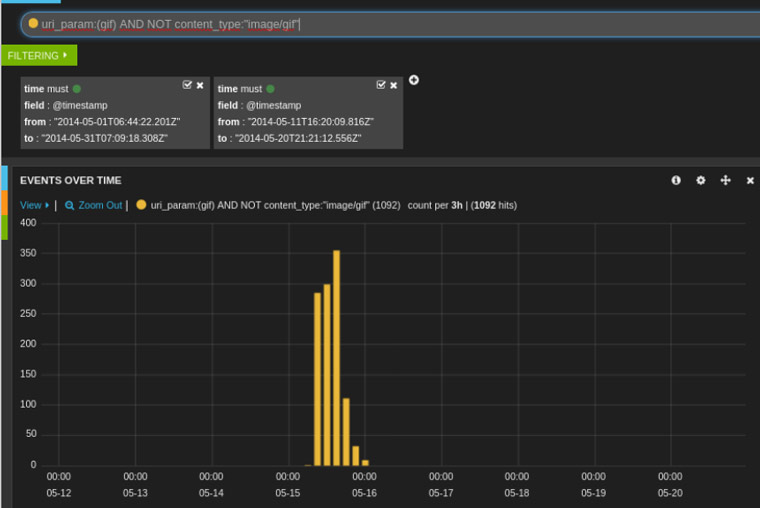
Otra búsqueda interesante, podría ser investigar qué peticiones nos están devolviendo 404 y un tamaño de respuesta superior a un determinado umbral que le especifiquemos o dentro de un intervalo (Ej: response_status:404 AND response_size:[1000 TO 100000]). Lo habitual quizá, es que el tamaño devuelto por un 404 no sea demasiado elevado:
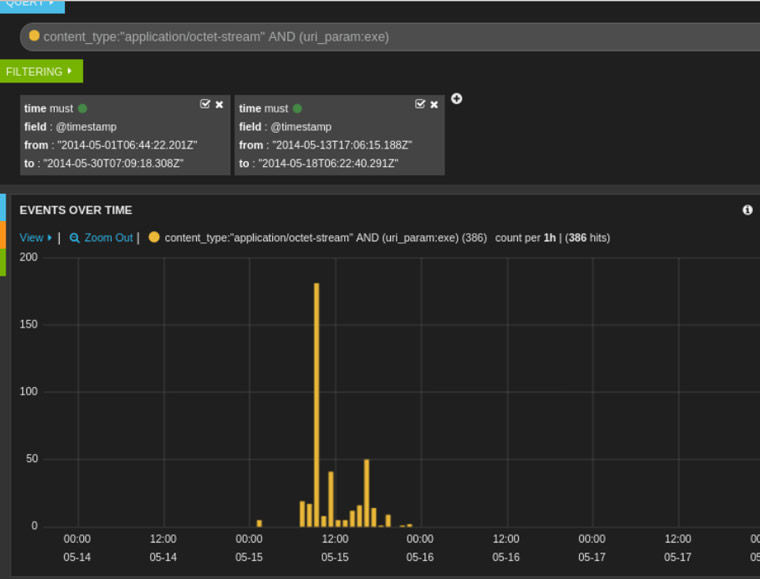
También podemos querer averiguar los “exe” que se han estado descargando:
Como vemos, las posibilidades de buscar anomalías son bastante amplias, y Kibana puede ser una buena herramienta para ayudarnos a complementar los análisis de nuestros logs. Personalmente echo en falta (o yo no he sabido implementarlo) un método que me permita calcular periodicidades en las conexiones, facilidad de integración con fuentes externas -para que sea capaz de correlar algunos datos- y que incorpore su propia base de datos de inteligencia, a la cual se la permitiera ir autoaprendiendo.
En este ejemplo hemos buscado algunas de las anomalías más conocidas, pero si tratamos de investigar registros procedentes de compromisos por ataques avanzados, que implican una mayor dificultad para encontrar evidencias de compromiso, una herramienta que nos amplía las posibilidades es CARMEN (Centro de Análisis de Registros y Minería de Eventos) [PDF] , pensada para la detección de amenazas persistentes avanzadas y fruto de proyectos de I+D+i y explotación de seguridad por parte del CCN (Centro Criptológico Nacional) y S2 Grupo, la cual está dotada de inteligencia, capacidad de autoaprendizaje y facilidad de integración con diferentes fuentes.
Aprovecho para comentar que, se ofrecerá un taller sobre CARMEN en las VIII Jornadas STIC CCN-CERT, que se celebraran el próximo diciembre. Allí os esperamos y para el que no pueda asistir, no os preocupéis que os lo iremos contando por aquí :)
Allí estaremos :)
Gracias Maria,
Un saludo :D
Maite, bueniiiiisimo. ahora bien tengo una duda.
……”CARMEN (Centro de Análisis de Registros y Minería de Eventos) [PDF] , pensada para la detección de amenazas persistentes avanzadas y fruto de proyectos de I+D+i y explotación de seguridad por parte del CCN (Centro Criptológico Nacional) y S2 Grupo, la cual está dotada de inteligencia, capacidad de autoaprendizaje y facilidad de integración con diferentes fuentes.”
¿De que tipo de inteligencia habeis dotado CARMEN?, (deje a medias mi tesis en el departamento de Inteligencia Artificial de la UNED), tengo mucha curiosidad.
Hola Tio Tonet :)
CARMEN busca usos indebidos y anomalías en los tráficos de red; para la capacidad de detección de anomalías -los usos indebidos son habas contadas- se basa en detección de anomalías estadísticas univariable y multivariable y detección de anomalías basada en conocimiento; el aprendizaje automático está en I+D aún :) Todo ello sobre campos, respuestas, cadenas de texto condicionadas… en definitiva sobre todo lo que se pueda obtener de un tráfico de red, especialmente los externos (exfiltración & C&C).
Gracias por el interés.
Saludos,
Maite Moreno