
Cada día vemos aparecer en el mercado nuevas tecnologías que permiten nuevas formas de desarrollo para la innovación. Sin ir más lejos, en el mundo de la web, la innovación conduce a la popularidad, haciendo que sitios como Google, Twitter y Facebook triunfen.
El principal problema de las nuevas tecnologías es que, aún teniendo la posibilidad de evitar problemas de seguridad conocidos, desafortunadamente, la mayoría de las veces esta no es el objetivo principal, por lo que estos errores se vuelven a repetir una y otra vez. Además de esto, las nuevas tecnologías también tienden a inventar nuevas clases de vulnerabilidad, o nuevas formas para explotar problemas de seguridad conocidos.
Un ejemplo práctico de que lo estoy diciendo es Node.js
¿Qué es Node.js?
 El 8 de noviembre de 2009, Ryan Dahl presentó Node.js como un entorno de desarrollo en JavaScript de lado de servidor, totalmente asíncrono y orientado a eventos. Usa el motor de JavaScript V8 de Google, dotando a este entorno de una gran velocidad y agilidad, y sumando además una capacidad de Entrada/Salida realmente ligera y potente. Esto permite construir aplicaciones altamente escalables y escribir código que maneje miles de conexiones simultáneas en un solo equipo. Entre las compañías que usan esta tecnología destacamos LinkedIn, eBay, Yahoo!, Microsoft y nosotros mismos (S2 Grupo).
El 8 de noviembre de 2009, Ryan Dahl presentó Node.js como un entorno de desarrollo en JavaScript de lado de servidor, totalmente asíncrono y orientado a eventos. Usa el motor de JavaScript V8 de Google, dotando a este entorno de una gran velocidad y agilidad, y sumando además una capacidad de Entrada/Salida realmente ligera y potente. Esto permite construir aplicaciones altamente escalables y escribir código que maneje miles de conexiones simultáneas en un solo equipo. Entre las compañías que usan esta tecnología destacamos LinkedIn, eBay, Yahoo!, Microsoft y nosotros mismos (S2 Grupo).
¿Qué es el V8?
V8 es el motor de JavaScript que Google usa en su navegador Chrome. Un motor normal de JavaScript, interpreta el código y lo ejecuta. El V8 es ultra-rápido, está escrito en C++ y se puede descargar por separado e incorporarlo a cualquier aplicación. Así nace Node.js, cambiando el propósito por el que se creó V8 y usándolo en el lado del servidor.

¿Para qué JavaScript en el lado del servidor?
La meta principal de Node.js es la de proporcionar una manera fácil de construir programas de red escalables. En lenguajes como Java™ y PHP, cada conexión genera un nuevo hilo con su respectiva reserva de memoria. Esto limita la cantidad de peticiones concurrentes que puede tener un sistema. Por ejemplo, un servidor muy común es Apache, el cual crea un nuevo hilo por cada conexión cliente-servidor. Esto funciona bien con pocas conexiones, pero a partir de 400 conexiones simultáneas, el número de segundos para atender las peticiones crece considerablemente. Así pues, Apache funciona bien en entornos clásicos, pero no es el mejor servidor para lograr máxima concurrencia.
Node.js resuelve este problema cambiando la forma en que se realiza una conexión con el servidor. En lugar de generar un nuevo hilo de SO para cada conexión, cada conexión entra en el bucle de ejecución y dispara el evento dentro del “pool” de trabajadores. De esta forma, nunca se quedará en punto muerto, dado que no se permiten bloqueos y no se bloquea directamente las llamadas de E/S, permitiendo así miles de sesiones concurrentes (en un sistema UNIX este límite puede rondar por las 65.000 conexiones).
¿Cuándo usar Node.js?
Node.js está extremadamente bien diseñado para situaciones en la que se espere una gran cantidad de tráfico y donde la lógica del servidor y el procesamiento requeridos sean sencillas para dar una respuesta lo antes posible. Node.js es especialmente bueno en aplicaciones web que necesiten conexiones persistentes con el navegador del cliente. Usando ciertas librerías, en concreto socket.io, puedes hacer que una aplicación envíe datos al usuario en tiempo real; es decir, que el navegador mantenga la conexión siempre abierta y reciba continuamente nuevos datos cuando se requiera. Hay que entender que, aunque se puede usar como servidor de páginas web “clásicas”, no se diseñó para ese fin. Algunos ejemplos de uso:
- Servicios Web que proporcionen APIs RESTful.
- “Timelines” de Twitter.
- Aplicaciones de única página.
- Videojuegos de varios jugadores.
- Aplicaciones tiempo real (Chats, cuadros de mando).
Node.js dispone de un gestor de módulos (librerías, plugins, frameworks) npm (Node Package Manager), que amplían la funcionalidad de este y facilitan tareas. En otro futuro post trataremos de hablar de varios frameworks típicos de Node.js, en concreto de Fusker, que es un firewall de aplicación que previene y maneja una gran cantidad de ataques en Node.js.
Entre estas librerías, destacaremos la ya nombrada Socket.io, que es una librería que nos permite manejar eventos en tiempo real mediante una conexión TCP. Socket.io la cual tiene como objetivo hacer que las aplicaciones en tiempo real sean posibles en todos los navegadores y dispositivos móviles, borrando las diferencias entre los mecanismos de transporte (WebSocket, Adobe® Flash® Socket, AJAX long polling, AJAX multipart streaming, Forever Iframe, JSONP Polling).
Estas comunicaciones se pueden poner detrás de un servidor clásico como podría ser Apache o Nginx tal y como explica Vicente Domínguez en su post.
Un poco de código
Para comenzar, podemos descargar Node.js de la página de la aplicación http://nodejs.org/, para varios sistemas. En mi caso he realizado las pruebas con la última versión (tar.gz) para Linux.
Una vez descargado y funcionando vamos a comenzar escribiendo la aplicación en un fichero js. Editamos un archivo “ejemplo-1.js” y escribimos el siguiente código:
var http = require('http');
http.createServer(function (req, res) {
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('Hello World\n');
}).listen(1337, '127.0.0.1');
console.log('Server running at http://127.0.0.1:1337/');
Ahora desde la consola lanzamos la aplicación:
$ node ejemplo-1.js
Para los que no estéis familiarizados con JavaScript, existen multitud de tutoriales en internet, no es el propósito de este post explicar línea por línea que hacen los programas. En resumen, vemos que “ejemplo-1.js” crea un servidor que escucha en el puerto 1337 y, ante cualquier petición a http://127.0.0.1 devuelve un texto plano “Hello World”.
En el siguiente post, apoyándome en la presentación que hizo Sven Vetsch (Redguard AG – www.redguard.ch) para el Application Security Forum de 2012, trataré de mostrar cómo pueden afectar las clásicas vulnerabilidades (XSS reflejado, inyección de JS en el servidor, ejecución de código remoto).



 El objetivo de esta entrada es mostrar una manera de hacer un poco más seguro el acceso a una aplicación web (login) si ésta no dispone de SSL (HTTPS). Para los que son duchos en la seguridad, puede que esto les pueda parecer simple, e incluso obvio, pero en muchas empresas de desarrollo de páginas web, ni se plantean lo peligroso que puede llegar a ser el envío de credenciales en claro a través de Internet.
El objetivo de esta entrada es mostrar una manera de hacer un poco más seguro el acceso a una aplicación web (login) si ésta no dispone de SSL (HTTPS). Para los que son duchos en la seguridad, puede que esto les pueda parecer simple, e incluso obvio, pero en muchas empresas de desarrollo de páginas web, ni se plantean lo peligroso que puede llegar a ser el envío de credenciales en claro a través de Internet.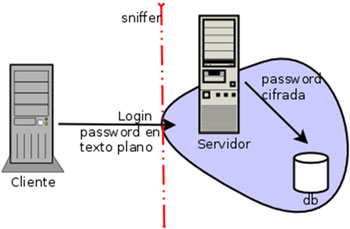 Normalmente suelen decir que hagas un hash de la contraseña y así esta no viajará en claro por la red. Esto no es una solución porque si yo soy un “hacker” maligno y consigo ver la comunicación, no podré leer la contraseña bob123, pero si que veré 2acba7f51acfd4fd5102ad090fc612ee, que es el resultado de aplicar una función
Normalmente suelen decir que hagas un hash de la contraseña y así esta no viajará en claro por la red. Esto no es una solución porque si yo soy un “hacker” maligno y consigo ver la comunicación, no podré leer la contraseña bob123, pero si que veré 2acba7f51acfd4fd5102ad090fc612ee, que es el resultado de aplicar una función  Creo que es de buena praxis cifrar, además de la contraseña, el nombre de usuario ya que cuantas menos pistas demos a los atacantes mejor. Así pues, cada vez que le mandemos la información de acceso al servidor, ésta será diferente, y aunque vieran que el usuario es 0a42b6b9dcd569f990d y la contraseña es cde40f4ff73c5a24eb904, esto sólo será válido una vez ya que a cada petición el servidor nos manda una clave pública distinta. Hay que tener mucho cuidado con esto, dado que si el servidor usa como semilla de generación de claves algo obvio, como el tiempo, se podría mediante repetidas peticiones de la página de login, obtener el algoritmo que esta usando para generarlas y podría llegar a obtener la clave privada para una petición y descifrar así la información.
Creo que es de buena praxis cifrar, además de la contraseña, el nombre de usuario ya que cuantas menos pistas demos a los atacantes mejor. Así pues, cada vez que le mandemos la información de acceso al servidor, ésta será diferente, y aunque vieran que el usuario es 0a42b6b9dcd569f990d y la contraseña es cde40f4ff73c5a24eb904, esto sólo será válido una vez ya que a cada petición el servidor nos manda una clave pública distinta. Hay que tener mucho cuidado con esto, dado que si el servidor usa como semilla de generación de claves algo obvio, como el tiempo, se podría mediante repetidas peticiones de la página de login, obtener el algoritmo que esta usando para generarlas y podría llegar a obtener la clave privada para una petición y descifrar así la información. En uno de los últimos portales web que he tenido que desarrollar una de las principales premisas era que tenía que ser muy seguro. El nuevo portal tenía que suplir a una versión hecha en html puro, sin código en el servidor. ¿Para qué cambiar si la versión anterior ya era segura? Tampoco entraré en más detalles pero, ¿os acordáis de esas “bonitas” webs con montones de gifs animados y colores espartanos? Esas páginas eran bonitas al lado de esta. Al grano. Para el desarrollo del nuevo portal se estuvieron haciendo pruebas con varios CMS (Gestores de contenidos) en PHP. ¿Por qué en PHP? Pues porque los recursos del servidor eran limitados, y porque me gusta. Al final nos decantamos por Drupal, ya que ofrecía a priori una robustez y seguridad que otros no. ¡Ah!, y porque me gusta.
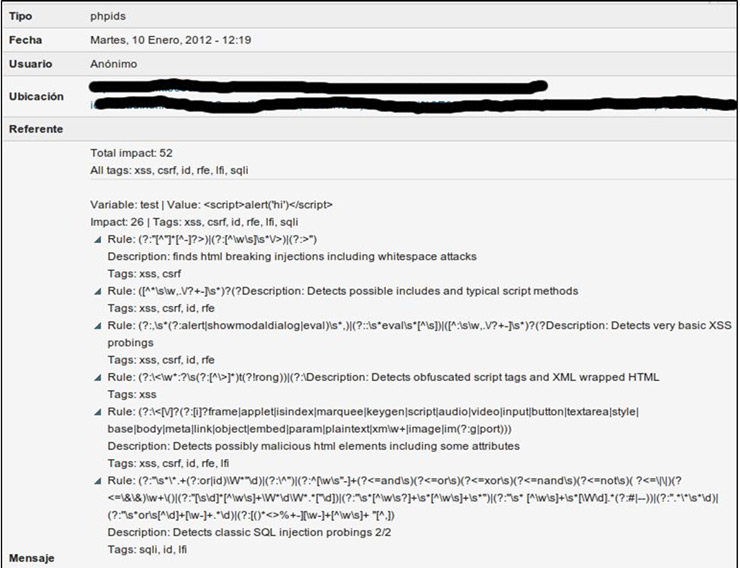
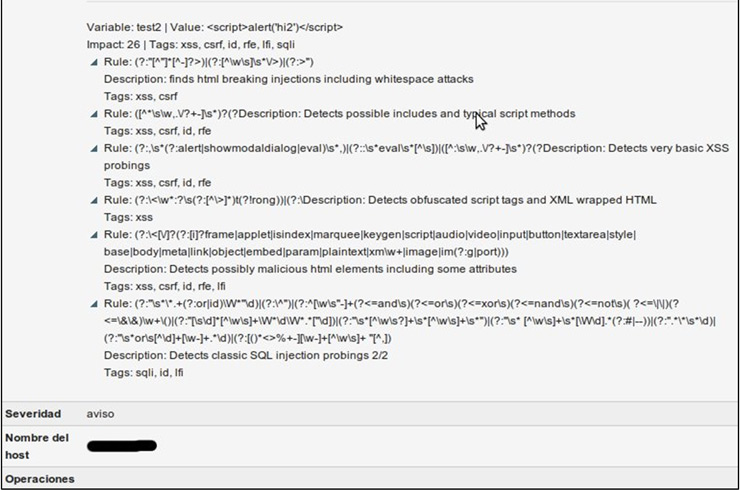
En uno de los últimos portales web que he tenido que desarrollar una de las principales premisas era que tenía que ser muy seguro. El nuevo portal tenía que suplir a una versión hecha en html puro, sin código en el servidor. ¿Para qué cambiar si la versión anterior ya era segura? Tampoco entraré en más detalles pero, ¿os acordáis de esas “bonitas” webs con montones de gifs animados y colores espartanos? Esas páginas eran bonitas al lado de esta. Al grano. Para el desarrollo del nuevo portal se estuvieron haciendo pruebas con varios CMS (Gestores de contenidos) en PHP. ¿Por qué en PHP? Pues porque los recursos del servidor eran limitados, y porque me gusta. Al final nos decantamos por Drupal, ya que ofrecía a priori una robustez y seguridad que otros no. ¡Ah!, y porque me gusta. Otra manera de usar PHPIDS es mediante el módulo de Drupal (ver la
Otra manera de usar PHPIDS es mediante el módulo de Drupal (ver la 
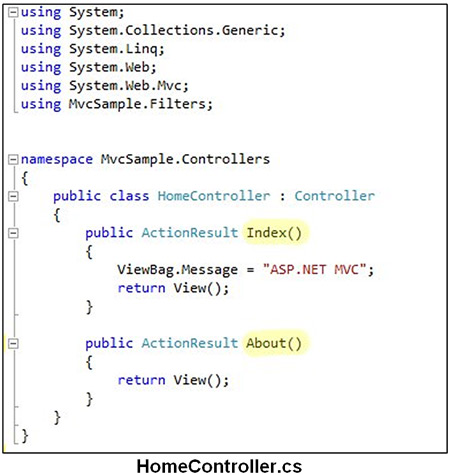
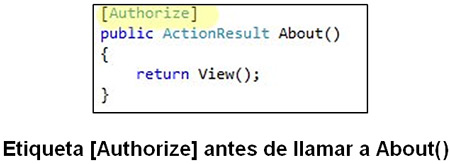
 El 24 de Abril de 1998 se publicó una versión corregida, de una publicación original del 18 de Diciembre de 1997, llamada HTML 4.0. Esta supuso un gran salto desde las versiones anteriores. Entre sus novedades más destacadas se encontraban las hojas de estilos CSS, la posibilidad de incluir pequeños programas o scripts en las páginas web, mejora de la accesibilidad, tablas complejas y mejoras en los formularios.
El 24 de Abril de 1998 se publicó una versión corregida, de una publicación original del 18 de Diciembre de 1997, llamada HTML 4.0. Esta supuso un gran salto desde las versiones anteriores. Entre sus novedades más destacadas se encontraban las hojas de estilos CSS, la posibilidad de incluir pequeños programas o scripts en las páginas web, mejora de la accesibilidad, tablas complejas y mejoras en los formularios.