A lo largo de estos últimos años hemos escrito sobre los honeypots y las ventajas que aportan a nuestra infraestructura. Por ello para intentar promulgar el uso de este tipo de herramientas he preparado un entorno virtual que emula varios honeypots de distintas clase formando una red completa: una honeynet.
Como tecnología de virtualización he escogido User Mode Linux por estar bastante familiarizado con ella, debido a que fue la opción escogida en mi proyecto de fin de carrera (véase http://bastionado.blogspot.com/2011/07/mi-proyecto-de-fin-de-carrera.html). Pero no solo por esto, ya que UML tiene una ventaja muy importantes respecto al resto de tecnologías: la máquina virtual es ejecutada con permisos de usuario sin privilegios, y por tanto, en caso de que un atacante consiga saltar al entorno anfitrión, éste accedería como usuario no privilegiado, es decir, sin ser root. De ahí su nombre, User Mode, ya que se ejecuta en el espacio de usuario y no en el espacio del kernel.
Como se puede ver en el siguiente diagrama, la Honeynet UML ha sido dividida en tres subredes: red de baja interacción, red de alta interacción y red de monitorización.
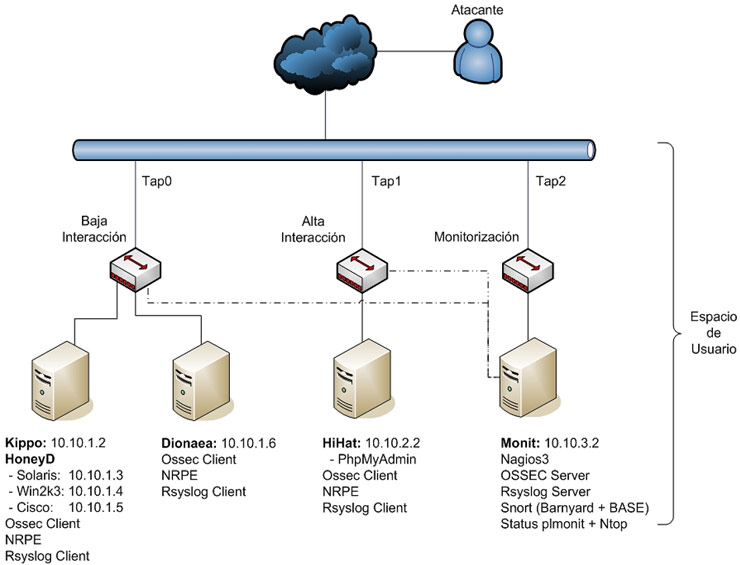
La red de baja interacción está formada por dos máquinas virtuales y un Hub UML. La primera tiene configurado un HoneyD con 3 plantillas diferentes: Solaris, Windows Server 2003 y un Cisco ASA. A su vez se ha empleado el honeypot Kippo que simula una shell de SSH. La segunda máquina UML tiene instalado un Dionaea que recientemente analizó Nelo.
La red de alta interacción está compuesta por una máquina virtual y un Hub UML. En ésta se ha instalado un honeypot de alta interacción (HIHAT) sobre un PhpMyAdmin.
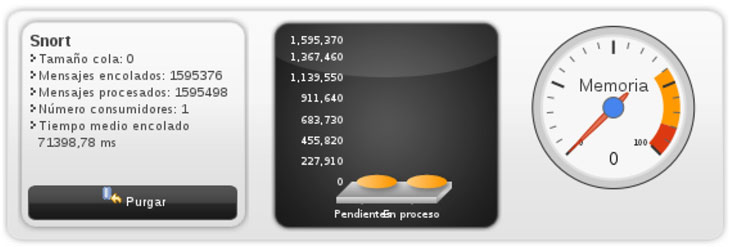
La red de monitorización está compuesta por una máquina virtual y un Hub UML. La máquina UML “Monit” tiene instalado una consola centralizada por Web con un OSSEC, Nagios3, Syslog centralizado , monitorización del tráfico de red, consola de gestión HIHAT y un Snort 2.9.1.2 con DAQ 0.62 que analiza el tráfico de las redes de baja y alta interacción.
Para poder ejecutar este entorno es necesario configurar primeramente el equipo anfitrión para crear las tres interfaces del entorno y habilitar el Masquerade de las máquinas virtuales:
# /honeynet/sbin/setup.sh on Making Taps... Tap0... [OK] Tap1... [OK] Tap2... [OK] Internet... [OK]
Una vez configurado las tres interfaces ya podemos lanzar la red virtual como usuario no privilegiado mediante la siguiente orden:
$ /honeynet/bin/honeynet.sh on
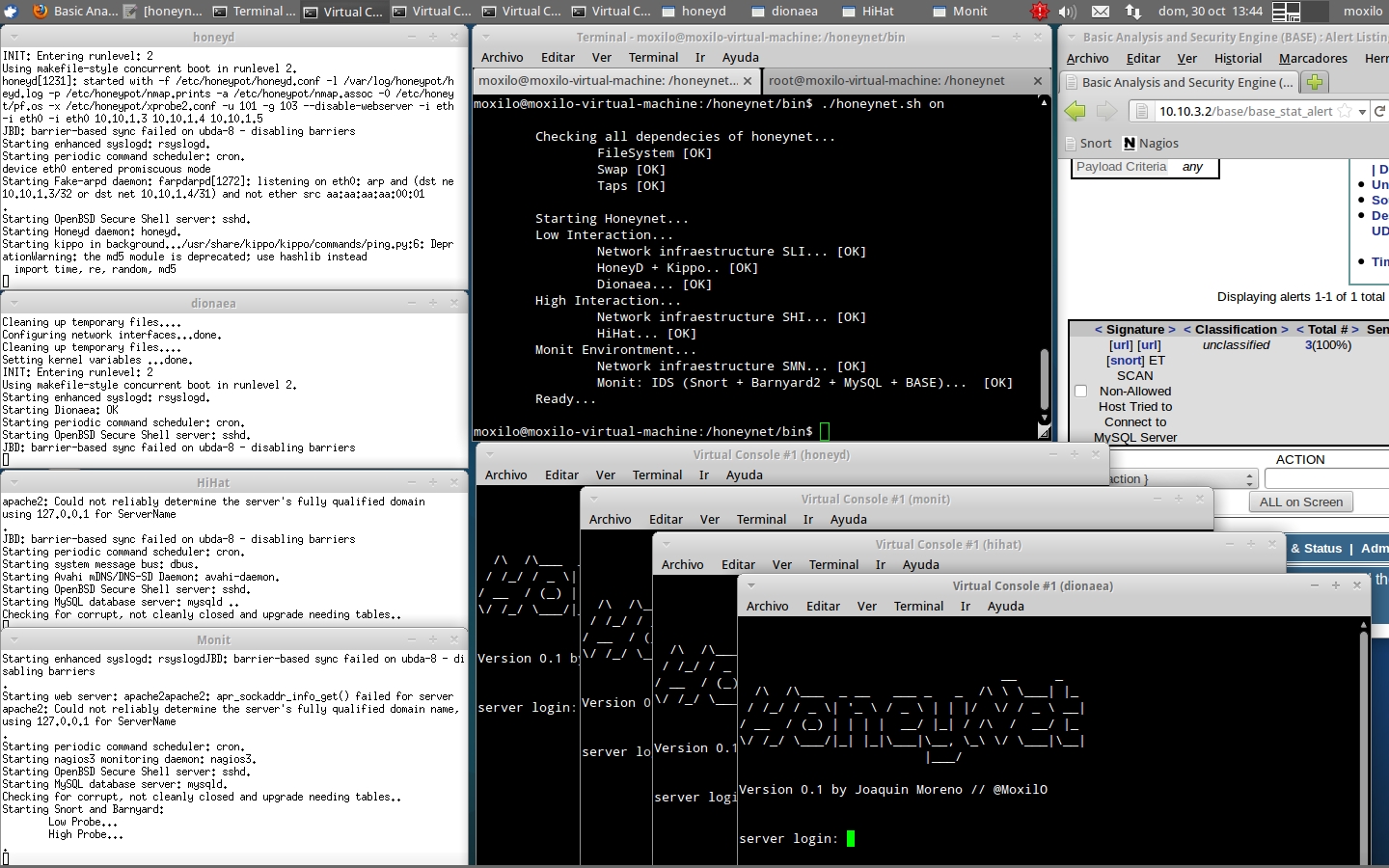
Dando como resultado la siguiente imagen, donde podemos ver a la izquierda las cuatro consolas de las cuatro máquinas virtuales UML, en la parte central superior la ejecución del script de la honeynet, en la parte central inferior las 4 terminales de las máquinas virtuales y por último a la derecha la consola de alertas BASE (Snort) notificando de conexiones a la MySQL de HiHat (al pinchar sobre la imagen, ésta se abrirá en una nueva ventana en tamaño grande):
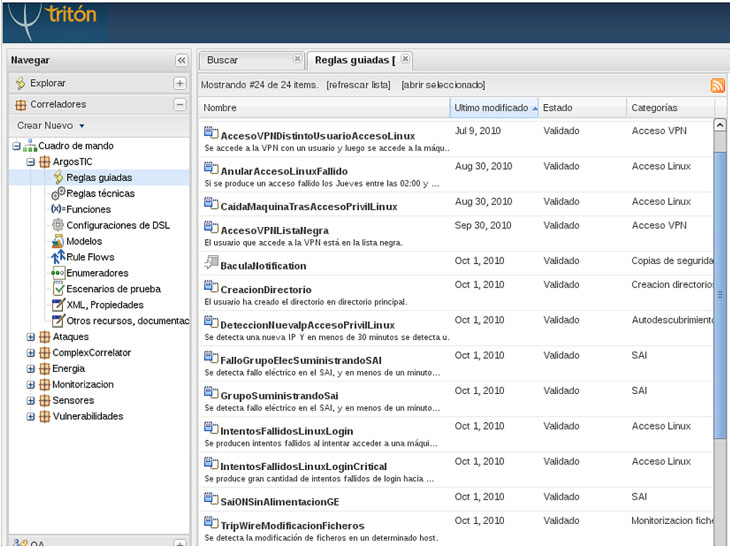
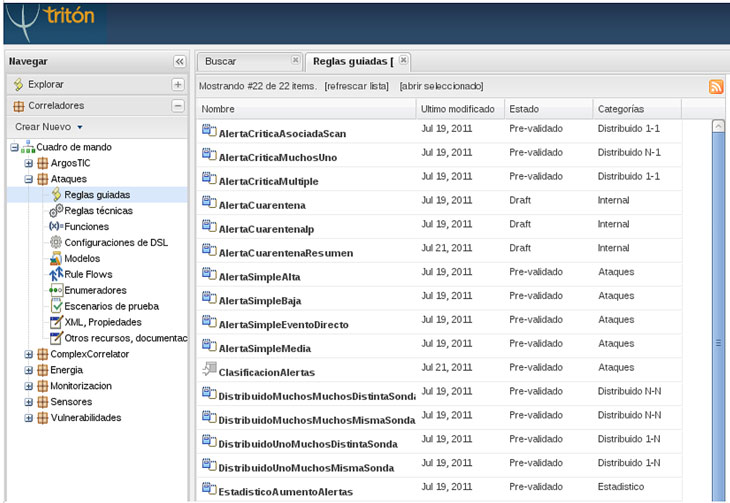
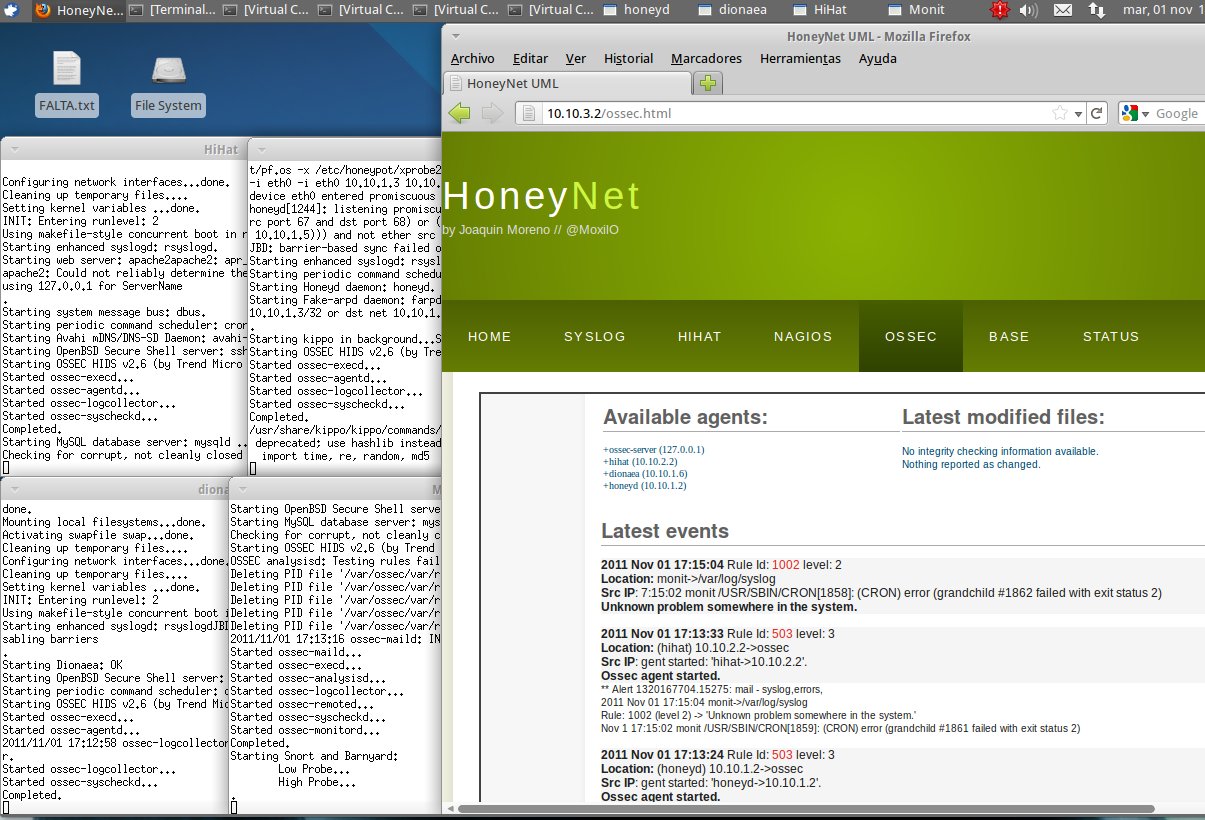
Para facilitar la administración he creado una consola web centralizada en el entorno de monitorización que nos permite gestionar las alertas generadas:
- Entorno BASE que nos permite gestionar las alertas de Snort.
- Interfaz Web de OSSEC para gestionar las alertas del HIDS.
- Gestión de las notificaciones del Syslog de todos los honeypots distribuidos mediante Rsyslog y LogAnalyzer.
- Monitorización de la disponibilidad del entorno con Nagios3.
- Status que muestra el estado de la red: que tipo de tráfico, paquetes perdidos, clasificación de IPs conectadas, etc.
Tal como se ilustra en la siguiente imagen (al pinchar sobre la imagen, ésta se abrirá en una nueva ventana en tamaño grande):
He intentado subir el entorno a algún servidor para que únicamente con descargarse el fichero, descomprimirlo y ejecutarlo, tal como hemos mostrado en las capturas de pantalla, tendríamos una Honeynet completa en nuestro entorno, pero el fichero completo ocupa 6 GB y me ha sido imposible alojarla en un servidor.
De forma temporal he subido los ficheros necesarios a Google Code, donde podéis descargar desde este enlace los scripts necesarios para la ejecución y configuración de la honeynet. Para crear las máquinas UML “solo” tenéis que seguir estos pasos, que todo sea dicho, es un poco quick and dirty con un inglés sin comentarios ya que la wiki fue creada en dos horas…
Si alguien tiene especial interés existe la posibilidad de subir el proyecto a Megaupload o algún otro servidor que permita alojar un fichero de 6 GB. No me gusta nada esta idea pero visto lo visto no veo otra opción.
Para finalizar indicar que el proyecto está abierto a cualquier persona que quiera colaborar, ya que —sea dicho de paso— toda la colaboración que la “comunidad” muestra en aspectos de hacking y reversing brilla por su ausencia en materia de defensa de entornos. Por alguna razón desconocida (corramos un tupido velo) en general son más populares las estrategias y técnicas de ataque que las de defensa. Vayan ustedes a saber porqué.