
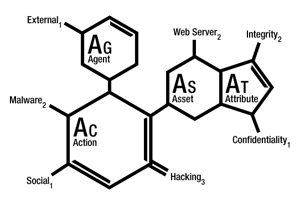
 Hace un par de semanas se realizó en Valencia una jornada de seguridad organizada por ISMS Forum donde pude asistir, entre otras, a una charla de Jelle Niemantsverdriet (el principal consultor forensics de Verizon), quien, aparte de remarcar la importancia de los logs para llevar a cabo sus análisis —importancia que también se ha remarcado en distintas entradas en este blog—, presento brevemente el framework VERIS desarrollado por Verizon.
Hace un par de semanas se realizó en Valencia una jornada de seguridad organizada por ISMS Forum donde pude asistir, entre otras, a una charla de Jelle Niemantsverdriet (el principal consultor forensics de Verizon), quien, aparte de remarcar la importancia de los logs para llevar a cabo sus análisis —importancia que también se ha remarcado en distintas entradas en este blog—, presento brevemente el framework VERIS desarrollado por Verizon.
El framework VERIS (Verizon Enterprise Risk and Incident Sharing) proporciona un lenguaje común para describir incidentes de seguridad de forma estructurada y repetitiva, basado en lo que denominan las cuatro ‘A’:
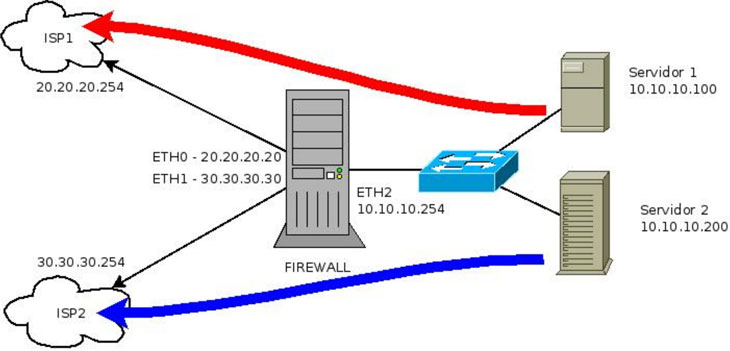
 Cuando hablamos de continuidad de negocio y planes de recuperación ante desastres, siempre nos vienen a la mente alternativas de recuperación del tipo Cold, Warm y Hot Sites dependiendo del RTO requerido por nuestra organización. No obstante, existen otras alternativas de recuperación menos conocidas (o al menos, menos aplicadas), por ejemplo los conocidos como Mobile Sites.
Cuando hablamos de continuidad de negocio y planes de recuperación ante desastres, siempre nos vienen a la mente alternativas de recuperación del tipo Cold, Warm y Hot Sites dependiendo del RTO requerido por nuestra organización. No obstante, existen otras alternativas de recuperación menos conocidas (o al menos, menos aplicadas), por ejemplo los conocidos como Mobile Sites.