Viviendo en la era digital no hay duda de que la información es un recurso muy valioso, y como mencionaba mi compañera María Ángeles en su entrada, el que tiene la información tiene el poder, pero ser capaz de sintetizarla y inferir nuevas evidencias o predicciones a partir de esta en un tiempo razonable es también muy importante.
Cada día se almacenan enormes cantidades de información, por lo que sistemas gestores de bases de datos relacionales están dando paso al fenómeno big data, que cada vez despierta más interés y expectativas en las organizaciones. De hecho, muchas empresas están abriendo nuevas líneas de negocio, creando plataformas SaaS que se dedican exclusivamente a analizar cantidades titánicas de información e identificar aquella que podría tener un valor importante para las decisiones estratégicas de muchas corporaciones.
Para aquellos que todavía no están familiarizados con el término, se trata de la nueva generación de tecnologías para el acceso, procesamiento, análisis y visualización de enormes volúmenes de datos. Entre estas surge toda una tipología de bases de datos NoSQL y plataformas de procesamiento big data, sistemas robustos que ofrecen elevadas capacidades de escalabilidad, baja latencia, y un esquema libre de modelo para el almacenamiento flexible de datos. Así, tenemos familias para el almacenamiento de datos en forma de clave-valor (key-value), orientados a colecciones, columnas, persistencia de estructuras de datos en forma de grafos, etc. Uno de ellos es Storm (el lector precavido ya puede estar intuyendo de donde proviene la inspiración para el título de esta entrada).
Storm es el sistema distribuido para el procesamiento de flujo de datos, actualmente propiedad de Twitter, aunque originalmente fue desarrollado por la compañía Blacktype. Fiable y tolerante a fallos, garantiza que cada mensaje inyectado en el flujo se procesará de forma completa. A diferencia de otras plataformas de procesamiento de datos como Hadoop o Cascading, Storm realiza el procesamiento del flujo de datos en tiempo real. El componente encargado de llevar a cabo ese procesamiento se llama topología. A su vez, ésta está formada por varias abstracciones que explicaremos más adelante. Cuando la carga computacional se incrementa de forma considerable se hace trivial aumentar el paralelismo de la topología para que se ejecute en varios procesos distribuidos en multitud de máquinas físicas. Si se produce un fallo durante el procesamiento, Storm se encargará de reasignar el trabajo a las tareas, además de garantizar que no habrá pérdida de ningún mensaje gracias a la naturaleza transaccional de las topologías. Otra de las ventajas de Storm, es que permite la ejecución de consultas distribuidas (DRPC) paralelizables al vuelo, ideal para los escenarios donde es necesario lanzar queries intensas u otras operaciones exigentes.
Es usado por multitud de organizaciones tales como Groupon, Alibaba, The Weather Channel, y como no, Twitter. Podemos ver la lista completa de empresas y proyectos que usan Storm. No tenemos que olvidarnos de mencionar que se trata de una plataforma open source, y aunque está desarrollada en una combinación de Clojure y Java, Storm es completamente agnóstico de lenguaje, por lo que nada nos limita a crear las topologías en otros lenguajes de programación.
El cluster de Storm está compuesto por dos tipos de nodos:
- Nodo maestro, es el nodo principal donde se ejecuta el demonio llamado Nimbus, encargado de asignar tareas a los nodos worker, monitorizar posibles fallos, distribuir el código a lo largo del cluster, etc.
- Nodos worker alojan el demonio llamado Supervisor que ejecuta la porción de la topología entre varios procesos que incluso puedan estar ejecutándose en múltiples máquinas.
La coordinación y el estado de ejecución entre los nodos se mantiene en ZooKeeper, o bien se persiste en disco duro cuando se ejecuta en modo local, y es precisamente esto lo que hace que Storm sea tan robusto y estable.
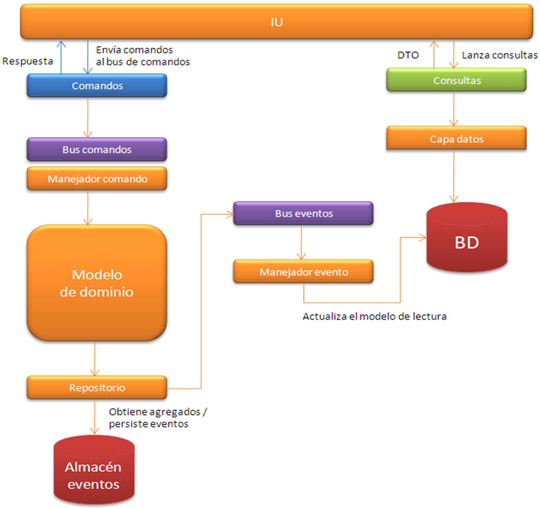
Las topologías se ejecutan continuamente hasta que se solicite explícitamente su terminación. Éstas están formadas por dos tipos de componentes que se agrupan en un grafo. Unos llamados spouts representan la fuente de entrada de flujo de datos en el sistema y generan listas de tuplas. Los spouts pueden inyectar datos en la topología bien consumiendo mensajes de las colas de los sistemas de mensajería, consultando la API de terceros vía REST, leyendo registros desde la base de datos, o cualquier otra fuente que se nos ocurra. Los bolts consumen las tuplas emitidas por spouts u otros bolts, para aplicar cualquier tipo de transformación o lógica específica al flujo de datos, ya sea filtrado, agrupaciones, funciones, agregaciones, etc. En el siguiente diagrama podemos ver la estructura simplificada del cluster de Storm.

Para dar un enfoque pragmático e ilustrar las capacidades de Storm, vamos a desarrollar una sencilla aplicación para procesar datos obtenidos desde las redes sociales. Usaremos el API de Facebook, para recuperar los estados que han ido publicando nuestros amigos y los mandaremos a una cola RabbitMQ. A continuación desarrollaremos los componentes de la topología – uno se encargará de consumir los mensajes de la cola y generar tuplas con el estado y el publicador (spout), y el resto aplicarán las transformaciones correspondientes para separar cada estado en palabras, contar las ocurrencias de las mismas y mostrar el top 20 de palabras más utilizadas en los estados de nuestros amigos en tiempo real. En la imagen podemos ver el grafo de spouts y bolts que forman nuestra topología.

El código completo de la aplicación se encuentra en el repositorio github, por lo que no vamos a entrar en detalles de implementación. Tan solo mencionaremos que los spouts deben implementar la interfaz IRichSpout y los bolts la interfaz IRichBolt. Los métodos importantes de los spouts, son nextTuple donde se obtiene el flujo de datos y se generan las tuplas, y el par ack / fail para confirmar o bien señalizar el fallo en el procesamiento de la tupla. Esto es importante, ya que la emisión de una tupla por un spout puede desencadenar la generación de muchas tuplas en otros componentes, por lo tanto se considera que un mensaje se ha completado satisfactoriamente cuando se procesa correctamente el árbol de tuplas generadas.
A la hora de ensamblar la topología podemos especificar las preferencias de paralelismo, tanto el número de tareas como el número de procesos workers. El último argumento del constructor de los componentes especifica el paralelismo. TopologyBuilder nos permite construir la topología que más tarde se desplegará en el cluster:
TopologyBuilder topologyBuilder = new TopologyBuilder();
topologyBuilder.setSpout("status-emitter", new AmqpStatusEmitterSpout() );
topologyBuilder.setBolt("status-splitter", new StatusSplittingBolt())
.shuffleGrouping("status-emitter");
topologyBuilder.setBolt("status-segmentator", new StatusSegmentatorBolt(),
5).fieldsGrouping("status-splitter", new Fields("word"));
StatusSegmentatorBolt se ejecutará de forma paralela entre 5 hilos de ejecución.
A raíz de todo lo que hemos dicho, podemos concluir que Storm es una plataforma prometedora y gracias a su modelo de programación sencillo, la curva de aprendizaje del mismo es corta y no tendremos que preocuparnos por detalles de sincronización, paralelismo o mantenimiento del estado y coherencia en el procesamiento de los mensajes.
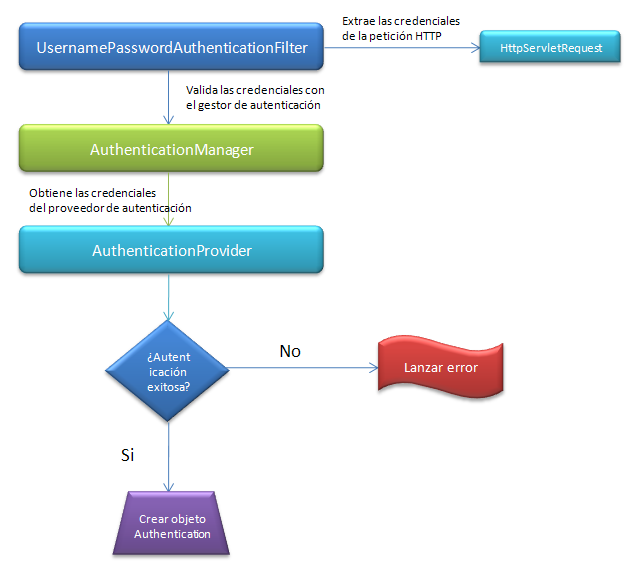
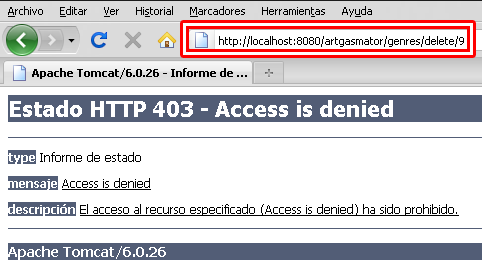
 Después de un considerable parón volvemos con un post cargado de temas interesantes sobre nuestro framework de seguridad favorito. En la
Después de un considerable parón volvemos con un post cargado de temas interesantes sobre nuestro framework de seguridad favorito. En la