
Hace ya tiempo presentábamos desde aquí qué era HoneySpider 2.0 y comentábamos por encima sus funcionalidades. Ahora vamos a ver una de las piezas fundamentales de esta nueva versión, como son los flujos de trabajo (workflow). Se asume por tanto que ya está instalado nuestro HoneySpider 2.0 o estamos usando la máquina virtual que han puesto desde el proyecto.
Partiendo de que ya tenemos la aplicación instalada debemos primero de todo tener a mano la documentación imprescindible para definir un workflow, que la podemos encontrar aquí y aquí.
Un workflow está compuesto en HoneySpider 2.0 por una serie de procesos, donde cada proceso está formado por servicios y estos servicios disponen de parámetros de entrada y la posibilidad de redirigir su salida a otros procesos. A continuación vemos como sería un esquema conceptual de lo que es un workflow:
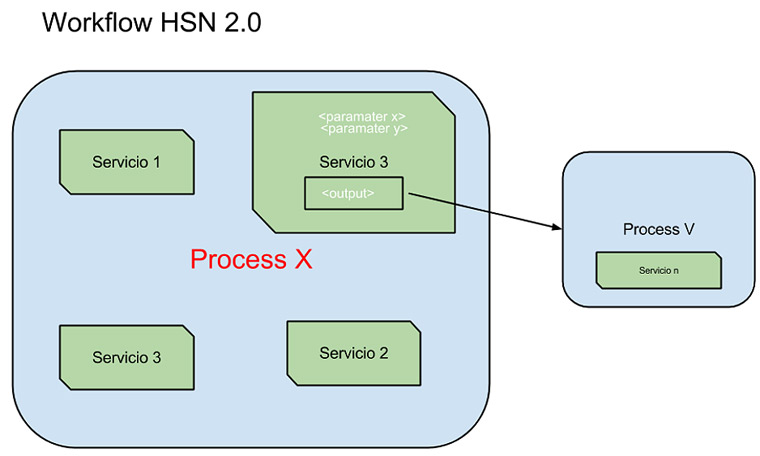
Estos flujos de trabajo se definen en formato XML. En el siguiente ejemplo os proporcionamos un workflow de ejemplo muy sencillo que realiza un análisis de ficheros office mediante la herramienta rb-officecat (Nugget de razorback) de un conjunto de enlaces:
<?xml version="1.0"?>
<workflow>
<description>
Analyze files office files with officecat
</description>
<process id="main">
<service name="feeder-list" id="feeder">
<parameter name="uri">/tmp/file.txt</parameter>
<parameter name="domain_info">true</parameter>
<output process="process_url"/>
</service>
</process>
<process id="process_url">
<service name="webclient" id="webclient0" ignore_errors="DEFUNCT">
<parameter name="link_click_policy">0</parameter>
<parameter name="redirect_limit">20</parameter>
<parameter name="save_html">false</parameter>
<parameter name="save_images">false</parameter>
<parameter name="save_objects">true</parameter>
<parameter name="save_multimedia">false</parameter>
<parameter name="save_others">false</parameter>
<output process="report"/>
</service>
<service name="reporter" id="reporter0">
<parameter name="serviceName">webclient</parameter>
<parameter name="template">webclient.jsont</parameter>
</service>
<!-- determine classification, taking into account propagation from child objects -->
<script>!findByValue("parent", #current).
{? #this.origin != "link" and #this.classification == "malicious"}.isEmpty
or rb_officecat_classification == "malicious"
? (classification = "malicious") :
(classification = "benign")</script>
<service name="reporter" id="reporter1">
<parameter name="serviceName"/>
<parameter name="template">url.jsont</parameter>
</service>
</process>
<process id="report">
<service name="reporter" id="reporter4">
<parameter name="serviceName">webclient</parameter>
<parameter name="template">webclient.jsont</parameter>
</service>
<service name="reporter" id="reporter5">
<parameter name="serviceName">file</parameter>
<parameter name="template">file.jsont</parameter>
</service>
<conditional expr="content != null and (mime_type == 'application/msword' or
mime_type == 'application/vnd.ms-excel' or mime_type ==
'application/vnd.ms-powerpoint')">
<true>
<service name="rb-officecat" id="office1"/>
<service name="reporter" id="reporter6" ignore_errors="INPUT">
<parameter name="serviceName">rb-officecat</parameter>
<parameter name="template">rb-officecat.jsont</parameter>
</service>
</true>
</conditional>
<!-- determine classification, taking into account propagation from child objects -->
<script>!findByValue("parent", #current).
{? #this.origin != "link" and #this.classification == "malicious"}.isEmpty
or rb_officecat_classification == "malicious"
? (classification = "malicious") :
(classification = "benign")</script>
<service name="reporter" id="reporter7">
<parameter name="serviceName"/>
<parameter name="template">url.jsont</parameter>
</service>
</process>
</workflow>
El workflow de ejemplo se debe interpretar de la siguiente manera: se define un proceso main que utiliza el servicio “feeder-list” para leer los enlaces a analizar de un fichero en /tmp/file.txt. Estos enlaces leidos se pasan al proceso process_url. Este proceso utiliza el servicio “webclient” para visitar esos enlaces, recibiendo como parámetro algunas acciones que debe hacer o no hacer, como guardar objetos multimedia, etcétera. Estos enlaces recopilados por este servicio se pasarán al proceso report.
Además de webclient el proceso process_url dispone de varios servicios que se encargan de generar información de salida para la interfaz web. Por último, el proceso report es donde se ha alojado el servicio que analiza los ficheros office con el nugget de razorback, “rb-officecat”, además de imprimir información mediante el servicio de report. Destacar la importancia de indicarle al servicio para qué tipo de contenido debe activarse; en este caso se le ha limitado a determinados tipos de contenido, para que entre en funcionamiento con contenidos que aplican.
Una vez cargado el workflow en nuestra herramienta, le proporcionamos un fichero con enlaces . En nuestro caso de ejemplo le hemos incluido un enlace con un fichero office malicioso, obteniendo como resultado:

Si hacemos clic sobre el documento detectado veremos la vulnerabilidad que ha detectado rb-officecat:
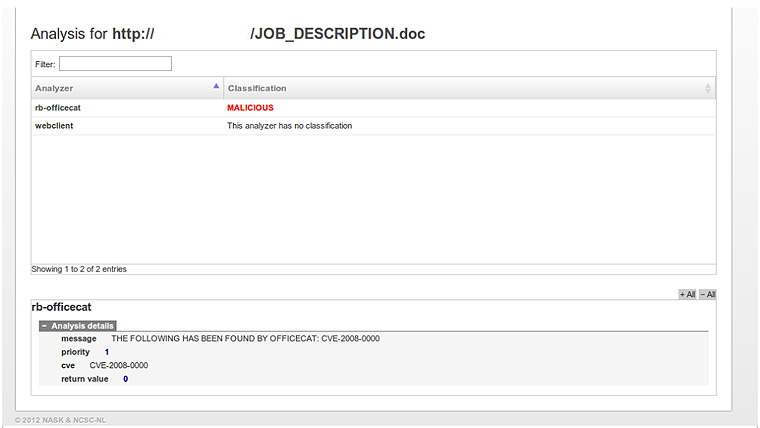
Este es solo un ejemplo de la detección que puede hacer esta herramienta. Como se ve es sencilla la definición y como ya comentamos en el post anterior con muchas posibilidades de ampliación. Decir que es una herramienta que está en una fase inicial y que ciertos aspectos será necesario pelearse hasta conseguir que funcionen como queremos o reportarlo en el grupo de Google de la propia herramienta.
Genial! es de esa clase de herramientas que nos descargan de mucho trabajo, buen aporte :)
Gracias!
Uau, pensé que ya no quedaban blogs tan técnicos. Gracias