
Son muchas las aplicaciones web que, como es lógico, protegen sus comunicaciones cifrándolas, con HTTPS por ejemplo. De acuerdo, a priori los datos que intercambiemos con la aplicación viajarán cifrados, estando a salvo de escuchas indiscretas. Pero ¿qué ocurre con estos datos de camino al navegador web?, es decir, entre el usuario que introduce los datos y el cliente web que establecerá la conexión con la aplicación.
Veamos lo que sucede desarrollando una pequeña prueba de concepto. Para ello, pondremos de ejemplo un par de sitios web mundialmente conocidos: Facebook y Linkedin, donde presumiblemente se invierte más en materia de seguridad y donde cada vez es más difícil detectar vulnerabilidades relevantes.
Accedemos a cada uno de los sitios y procedemos a autenticarnos (seguro que tenemos cuenta en ambos). Nos ponemos a la escucha del proceso de autenticación, utilizando un proxy como BurpSuite o, para este caso, alguno menos potente, como el complemento de Firefox denominado Live HTTP Headers.
Como podemos observar en las ilustraciones 1 y 2, se interceptan claramente los nombres de los campos del formulario donde se introducen las credenciales, además de los valores que contienen, todo en texto claro.
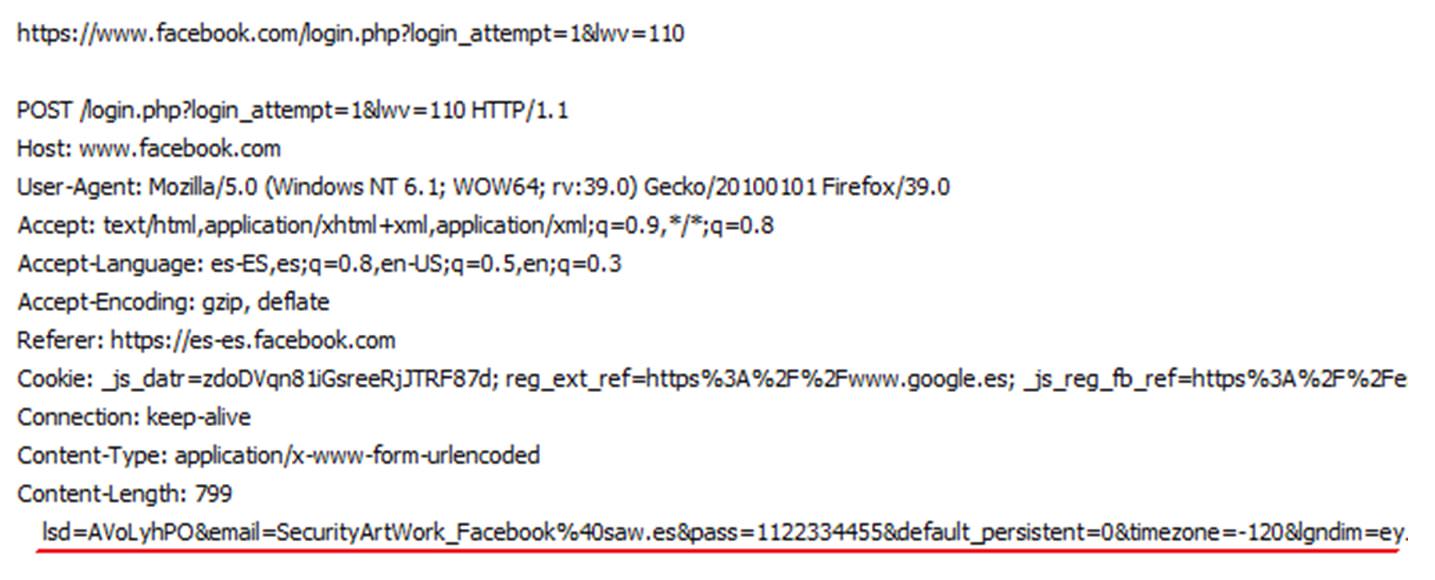 Ilustración 1: Interceptando autenticación en Facebook
Ilustración 1: Interceptando autenticación en Facebook
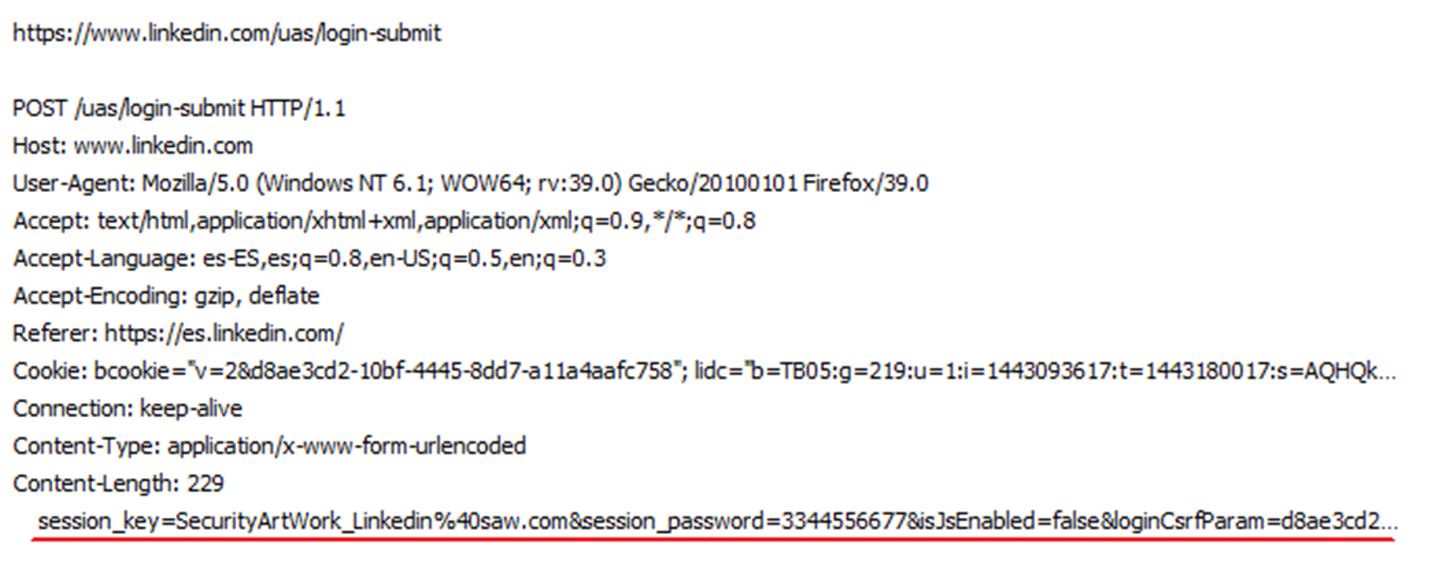 Ilustración 2: Interceptando autenticación en Linkedin
Ilustración 2: Interceptando autenticación en Linkedin
Este funcionamiento no es el adecuado, ya que pensemos lo que ocurriría si un usuario está infectado con el típico malware/adware que realiza Browser Hijacking (algo muy común en la mayoría de usuarios de todo el mundo), es decir, que interfiere en el normal uso del navegador web por parte del usuario monitorizando su actividad. Éste tendría la capacidad de interceptar las citadas comunicaciones entre usuario y cliente web, obteniendo credenciales de multitud de sitios web, no solo los mencionados como ejemplo. Son muchas las páginas web que contienen esta deficiencia, incluso sitios especialmente sensibles. Es lo que se denomina Man-In-The-Browser (MitB).
Este comportamiento también puede ser interesante en el ámbito forense, ya que, en la mayoría de ocasiones, esta actividad queda grabada en memoria. Realicemos una pequeña prueba para demostrarlo.
Como ejemplo, tenemos un entorno con el sistema operativo Windows 7, aunque el esquema a seguir es similar para otros sistemas. Comenzamos realizando una captura de la memoria RAM, utilizando para tal fin la herramienta DumpIt. Basta con ejecutarla y confirmar que deseamos realizar la captura de memoria (ilustración 3).
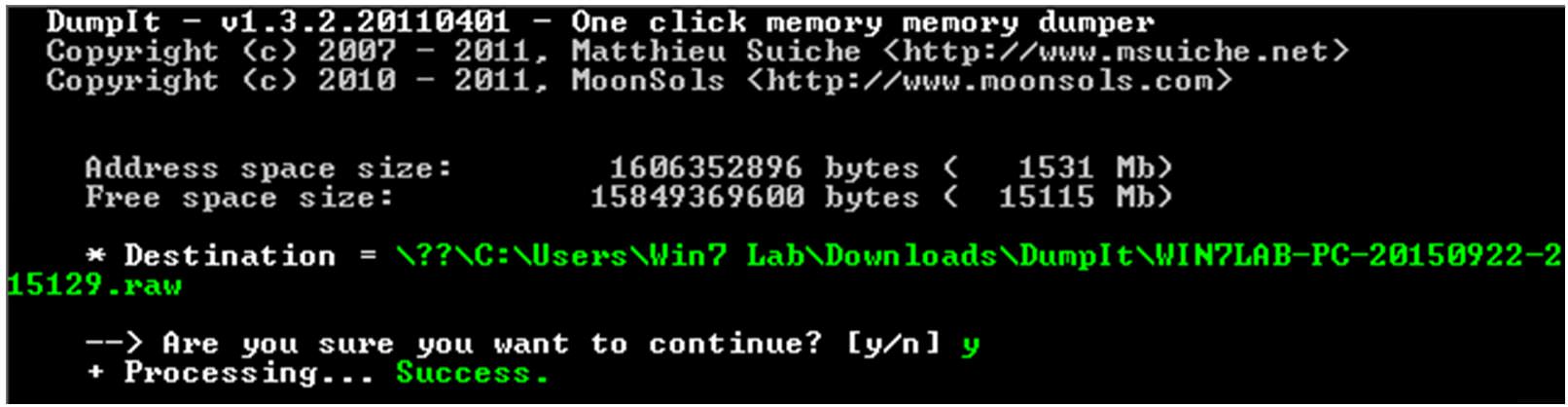 Ilustración 3: Realizando captura de memoria RAM con DumpIt
Ilustración 3: Realizando captura de memoria RAM con DumpIt
Analicemos ahora dicha captura con Volatility Framework (versión 2.4). En primer lugar, obtenemos información acerca de la captura de memoria que estamos analizando:
python vol.py -f WIN7LAB-PC-20150922-215129.raw imageinfo
Como se puede observar en la ilustración 4, podemos determinar, entre otras cosas, el profile de la captura de memoria, útil para indicarle a Volatility qué se está analizando. Como ya hemos comentado, se trata de un Windows 7 de 64 bits (Win7SP1x64).
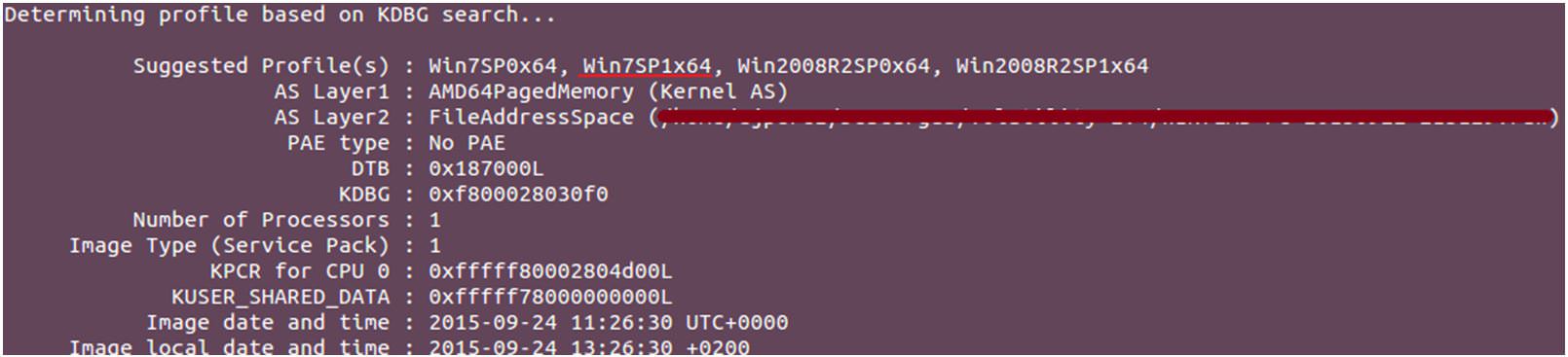 Ilustración 4: Obteniendo información de la captura de memoria
Ilustración 4: Obteniendo información de la captura de memoria
Obtenemos ahora el listado de los procesos en memoria (ilustración 5):
python vol.py -f WIN7LAB-PC-20150922-215129.raw --profile Win7SP1x64 pslist
 Ilustración 5: Listado de procesos en memoria
Ilustración 5: Listado de procesos en memoria
En nuestro caso, nos interesa especialmente el proceso del o de los navegadores web que hubiera abiertos en el momento de la intervención. Por tanto, debemos extraer dicho proceso (ilustración 6), pero incluyendo también todas las páginas en memoria que estuviera utilizando, que es donde se encuentra la información relevante.
python vol.py -f WIN7LAB-PC-20150922-215129.raw --profile Win7SP1x64 memdump -p 3304 --dump-dir ./
 Ilustración 6: Extrayendo proceso firefox.exe
Ilustración 6: Extrayendo proceso firefox.exe
Ahora que tenemos el proceso, con la ayuda de strings, podemos ver el contenido imprimible. Podemos comprobar, realizando un simple grep, que, efectivamente, las comunicaciones identificadas quedan almacenadas en memoria.
![]() Ilustración 7: Patrón almacenado en memoria
Ilustración 7: Patrón almacenado en memoria
Siempre se sigue el mismo patrón en el proceso de autenticación de cada uno de los sitios web de ejemplo. Esto nos facilita la creación de un pequeño script en python3 que automatiza la extracción de credenciales (parserTest.py), tal y como se aprecia en la ilustración 8.
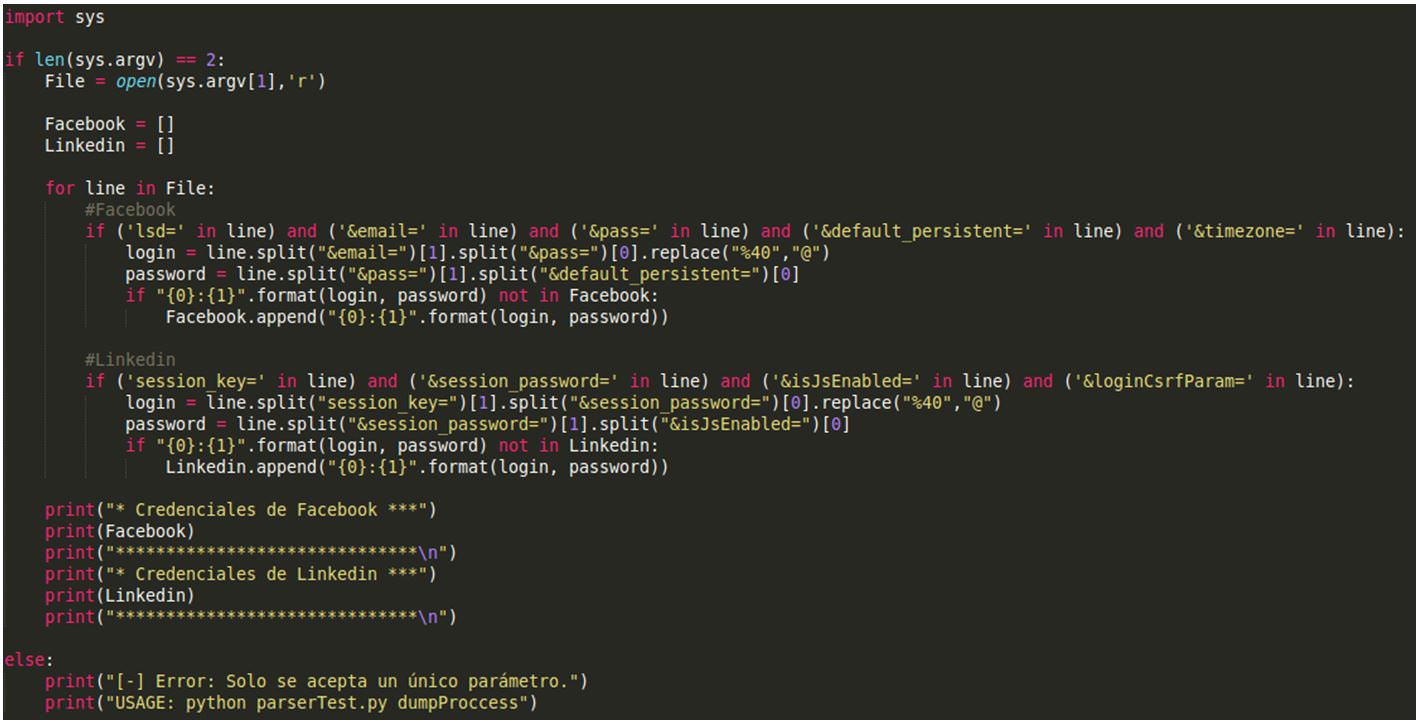
Ilustración 8: Código parserTest.py
El funcionamiento del script es muy simple, analiza cierto contenido pasado como parámetro en busca de los patrones identificados. Según el caso, estaremos hablando de unas posibles credenciales de Facebook o Linkedin. Como observamos, está especialmente diseñado para esta prueba de concepto, pero se puede extrapolar a otros casos, solo hay que completarlo.
Terminamos esta prueba de concepto, utilizando el comentado script para automatizar la extracción de credenciales en claro. Para ello, volcamos la salida de strings a un fichero, y ese fichero es el que pasamos como parámetro a nuestro pequeño extractor. Finalmente, como se puede observar en la ilustración 9, conseguimos obtener las claves.
strings 3304.dmp > firefoxStrings python parserTest.py firefoxStrings
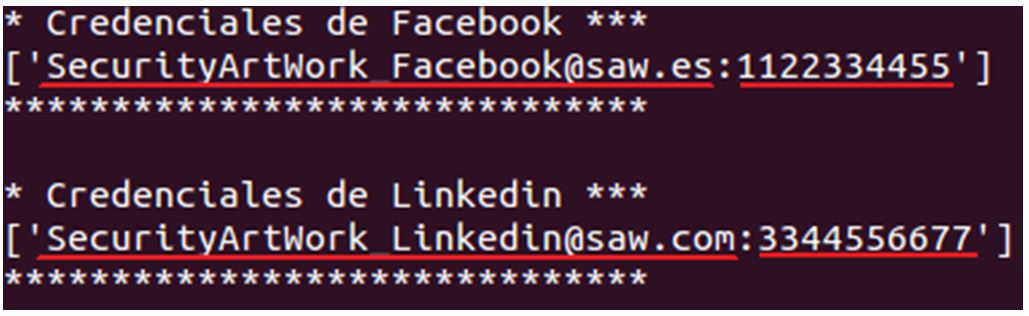 Ilustración 9: Obteniendo credenciales en claro
Ilustración 9: Obteniendo credenciales en claro
¿Cómo solventar el problema?
El comportamiento que aquí se comenta es bien fácil de solucionar. Para empezar, el nombre de los campos del formulario de autenticación se debe randomizar, es decir, cada vez que se cargue la página, el nombre de los campos (input) será diferente. De esta forma, no se podrán identificar los elementos que pueden contener información sensible.
A continuación, debe establecerse algún algoritmo de codificación para los parámetros de entrada, es decir, cada vez que se introduzca un carácter en un campo input que pueda ser sensible, se debe codificar de cierta forma. De esta manera, las credenciales ya no estarán en claro y tampoco se podría identificar una posible contraseña dado un nombre de usuario o email, ya que ambos estarán codificados, así como los campos que lo contienen.
Con estas sencillas técnicas mejoraríamos la seguridad de la aplicación web, evitando que nuestras credenciales sean susceptibles a escuchas o extracción a partir de memoria RAM.
Excelente nota. La verdad es que si el adversario obtiene un volcado de memoria ya estamos bastante perdidos (y desafortunadamente en algunos sistemas esto se puede lograr sin siquiera tocar el teclado). Dicho esto, siempre es bueno ponerle una barrera más al adversario y no regalarle el botín.