
This post and the full series has been elaborated jointly with Ana Isabel Prieto, Sergio Villanueva and Luis Búrdalo.
In previous articles of this series (see part I and part II) we described the problem of detecting malicious domains and proposed a way to address this problem by combining various statistical and Machine Learning techniques and algorithms.
The set of variables from which these domains will be characterized for their subsequent analysis by the aforementioned Machine Learning algorithms was also described. In this last installment, the experiments carried out and the results obtained are described.
The tests have been carried out against a total of 78,661 domains extracted from the a priori legitimate traffic of an organization, from which 45 lexical features belonging to the categories described above have been calculated.
Parameters
Each of the algorithms discussed above was tuned using a single parameter:
- Isolation Forest algorithm has been adjusted by the value of the parameter “contamination”. This parameter indicates the maximum proportion of outliers in the data set; that is, the higher the value of this parameter, the more data will be detected as outliers.
- In the case of the One-class SVM algorithm, the adjustment parameter is “nu”, whose value can be between 0 and 1. This parameter indicates an upper limit of the fraction of training errors (maximum proportion of outliers expected in the data) and a lower limit of the fraction of support vectors (minimum proportion of points in the decision boundary). In this way, this parameter allows to adjust the trade-off between overfitting and generalization of the model.
The following 5 malicious domains related to phishing campaigns and malware downloading have been introduced in the dataset, together with all the other data. These are the examples used in this paper to determine the efficiency of ML algorithms in detecting malicious domains.
- ukraine-solidarity[.]com
- istgmxdejdnxuyla[.]ru
- correo-servico[.]com
- hayatevesigar-10gbnetkazan[.]com
- 5748666262l4[.]xyz
The tests have been performed with the following values for the parameters:
| Modelo | Parámetro | Valor |
| Isolation Forest | Contamination | 0.002 |
| One Class SVM | nu | 0.002 |
Results and detections
With the above parameters, the more than 78,000 domains studied are reduced to 359 by at least one of the two unsupervised models, without applying any weighting on them. Of the 5 malicious domains chosen to evaluate the reliability, 3 of them are detected, being:
| Dominio | Isolation Forest | One Class SVM |
| istgmxdejdnxuyla[.]ru | — | X |
| hayatevesigar-10gbnetkazan[.]com | — | X |
| 57486662l4[.]xyz | X | X |
As discussed above, with PCA, the principal components necessary to explain 95% of the variance are extracted. In this case, a total of 15 principal components are extracted, which are going to be the features that the ML algorithms are going to use to detect the anomalous domains.
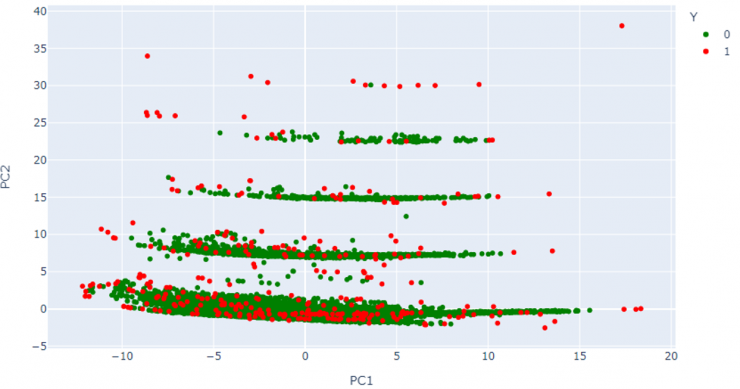
Figure 5 shows the 2D representation of the first two components (PC1, PC2), where different groupings of data can be observed according to their lexical characteristics. In it, the domains that are considered legitimate are shown in green and those that are marked as anomalous are shown in red. The fact that a domain moves away from a group indicates that it contains characteristics different from those of that group. Thus, the more a domain deviates from the other domains in the dataset, the more likely it is to be detected as anomalous.
It should be noted that, although some of the domains classified as anomalous do not appear to depart from the rest in this two-dimensional representation, there are 13 additional dimensions that the algorithms take into account, therefore, in some of them these domains must be significantly separated from the rest.
To reduce the number of anomalous domains to review, the list of the 10000 most common Alexa domains is used. Of the initial 359 anomalous domains, 21 belong to this list, leaving a total of 338 anomalous domains.
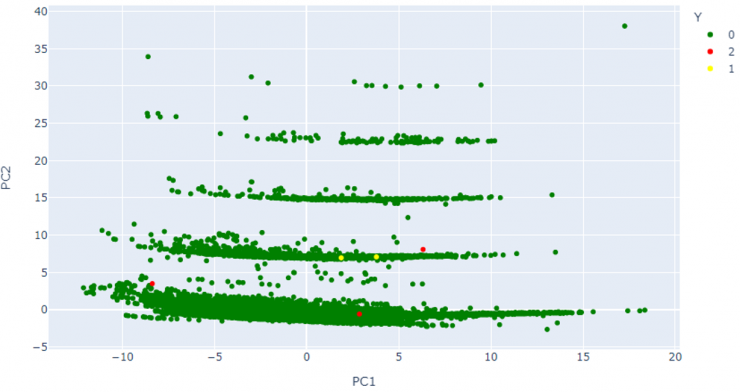
Figure 6 shows the same representation, but highlighting with different colors the malicious domains added a posteriori in this database, both those detected as anomalous by the models and those not detected.
Conclusions
This series of articles shows an example of how to employ ML algorithms to detect anomalies, thus drastically reducing the amount of information to be reviewed by analysts and also contributing to the automation of the hunting and detection process.
The algorithms have greatly reduced the data pool (338/78,000 = 0.0043; i.e., the set of domains to be reviewed has been reduced by approximately 99.6%). The ML algorithms used in this example were able to identify 3 of the 5 malicious domains entered in the test database.
The malicious domains not detected as anomalous were ukraine-solidarity[.]com and correos-servico[.]com. If these domains are analyzed, it is clear that the probable cause for this is that the lexical characteristics of both are very similar to those of commonly legitimate domains.
Although they have not been described in this article for the sake of not being too long, multiple tests have been carried out with different values of the “Contamination” and “nu” parameters of the algorithms. The results of these tests showed that both algorithms are very sensitive to these parameters. In order to significantly reduce the amount of initial information to be manually reviewed by the analysts without losing classification accuracy, it is desirable to use low values for these parameters. However, this can lead to a large number of false negatives, failing to correctly detect a large number of malicious domains. The correct setting of these parameters has to be carried out carefully.
One possible way to deal with this problem may be the correlation of different detection methods, both traditional rule-based and those using AI or ML algorithms.