
Desde la aparición de las redes sociales se ha ido concienciando poco a poco a los usuarios del peligro de compartir cierta información con los demás. Una de estas redes sociales, cada vez más popular y que en general y a diferencia de otras, proporciona la información publicada por un usuario a otros sin restricciones de acceso, es Twitter. Esta red ha cumplido 7 años desde su lanzamiento (muchos tweets que contar…) y parece que la mayoría de los usuarios todavía no están concienciados acerca de la privacidad, como suele ser habitual.
Como sabemos Twitter permite dos tipos de cuentas: las protegidas, cuyos tweets son accesibles sólo a las personas “autorizadas”, y las cuentas desprotegidas, cuyos tweets son accesibles a cualquier usuario. Dejando de lado que, tal y como sucede en otras redes sociales, un tweet “protegido” deja de serlo cuando un usuario sin la cuenta protegida lo “retuitea”, ¿qué ocurre con las cuentas de Twitter no protegidas? Éstas no sólo permiten a las personas seguir tu timeline sin necesidad de tu autorización (ie. hacerse “seguidores”), sino que además permite que cualquier usuario de Twitter, seguidor o no de tu timeline, pueda leer tus tweets. Es una ventana abierta pública a todo lo que escribimos. Esto tiene sus ventajas, pero también sus inconvenientes.
Para ver porqué esto puede ser en ciertos casos un problema, vamos a hacer uso de TweetDeck, uno de múltiples clientes que permiten añadir “columnas” según criterios de búsquedas e incluso el timeline de una persona, a la que no tenemos porqué “seguir” y que podemos por tanto “monitorizar” sin su conocimiento. Veamos un ejemplo:
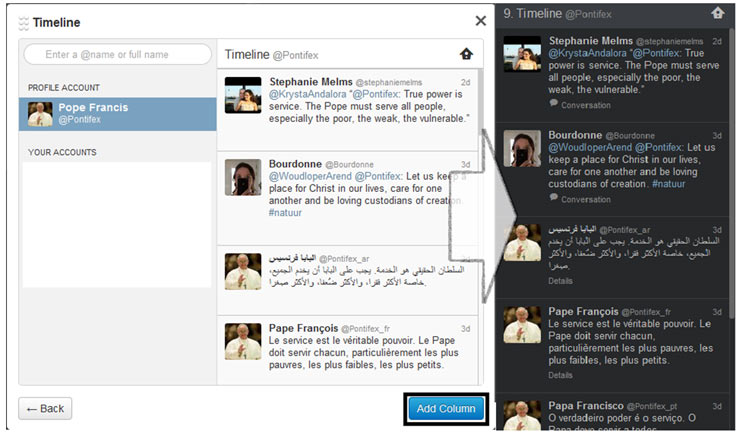
¿Qué información comparte la gente por Twitter?
No es la primera vez, ni será la última, que los usuarios comparten información privada y en ocasiones confidencial a través de medios menos que óptimos. Esto da como resultado, como ya se ha visto a lo largo de otras entradas en este y otros blogs, que información que no debería ser a priori pública, esté al alcance de cualquier persona con un poco de curiosidad y/o maldad. Sólo hay que hacer una búsqueda con ciertas palabras clave e indagar en los tweets obtenidos.
¿7 años después?
No importa los años que lleve Twitter en marcha, los nuevos usuarios se registran y la mayoría de ellos, sin preocuparse en las opciones de seguridad/privacidad que nos ofrece esta red social (muy inferiores, desde luego, por su distinta naturaleza, al caso de Facebook), comienza a enviar Tweets públicamente. Unos comparten fotos (personales, de tarjetas de crédito/débito, comprometidas, etc.), mientras que otros usuarios más “atrevidos” comparten información sensible como su número de teléfono, su correo electrónico o incluso contraseñas. Eso, dejando de lado salidas de tono que a diario cometen personalidades, políticos, deportistas, etc. Aunque parecería que ante este tipo de cosas es suficiente con borrar el Tweet, sólo hay que pasarse, por ejemplo, por topsy y muchos de estos tweets públicos aunque hayan sido borrados todavía estarán cacheados, pudiéndose consultar perfectamente.
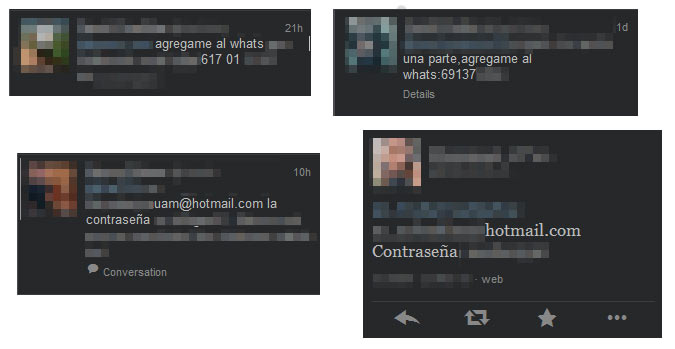
Conclusiones
A estas alturas huelga decir que falta concienciación entre muchos usuarios de las redes sociales, y Twitter no es una excepción. Es muy preocupante que los usuarios compartan información tan sensible entre sus contactos, sin ser conscientes de que cualquier persona puede leerlo. En general, el ego representado en el número de followers ha asumido como estándar una configuración abierta, donde un número relativamente bajo de usuarios tienen cuentas protegidas, a diferencia de otras redes sociales donde “parece” que empieza a existir una cierta comprensión de las implicaciones de una cuenta abierta. En este caso, cabe aplicar el sentido común y ser consciente de las implicaciones de nuestras publicaciones. En cualquier caso, siempre es útil rememorar que PLBKAC.
Lanzo una pregunta al aire, ya que muchos usuarios desconocen o no se preocupan por la privacidad: ¿debería establecerse por defecto la cuenta protegida?
(N.d.E. Dejemos aparte las implicaciones que esto tendría para la expansión de Twitter y su modelo de negocio)
 El tercer día de la /RootedCON se presentó igualmente interesante a pesar del cansancio acumulado. Prueba de ello fue la gran asistencia desde la primera charla que nos presentó la gente de
El tercer día de la /RootedCON se presentó igualmente interesante a pesar del cansancio acumulado. Prueba de ello fue la gran asistencia desde la primera charla que nos presentó la gente de  Justo antes del café Jesús Olmos nos presentó ChromeHack un complemento del popular navegador de Google para la auditoría Web. La verdad es que me sentí muy identificado cuando comentó el origen del proyecto, el hecho de estar realizando un análisis y tener: una Hackbar, el Tamperda, Burp, Pipper, 2 escritorios, y siete consolas abiertas, hace que el test acabe siendo un infierno. Es por eso que, este maravilloso plugin permite realizar con un simple botón derecho del ratón contra un recurso HTML concreto: fuerza bruta a un login, inyección SQL o XSS a formularios, fuzzing de URLs, todo ello basado en diccionarios de ataque. La verdad es que tenemos muchas ganas de probarlo y alimentarlo por ejemplo con los diccionarios del gran Pipper.
Justo antes del café Jesús Olmos nos presentó ChromeHack un complemento del popular navegador de Google para la auditoría Web. La verdad es que me sentí muy identificado cuando comentó el origen del proyecto, el hecho de estar realizando un análisis y tener: una Hackbar, el Tamperda, Burp, Pipper, 2 escritorios, y siete consolas abiertas, hace que el test acabe siendo un infierno. Es por eso que, este maravilloso plugin permite realizar con un simple botón derecho del ratón contra un recurso HTML concreto: fuerza bruta a un login, inyección SQL o XSS a formularios, fuzzing de URLs, todo ello basado en diccionarios de ataque. La verdad es que tenemos muchas ganas de probarlo y alimentarlo por ejemplo con los diccionarios del gran Pipper. Un año más estamos en la
Un año más estamos en la 




