(Esta es una historia de ficción; los personajes y situaciones no son reales; lo único real es la parte tecnológica, que se basa en una mezcla de trabajos realizados, experiencias de otros compañeros e investigaciones llevadas a cabo.)
Según lo visto en la entrada anterior (ver parte I, parte II y parte III), teníamos a nuestra disposición las siguientes evidencias digitales:
- Volcado lógico de un iPhone5.
- Volcado físico de un Samsung Galaxy S5.
- Imagen forense de un Apple MacBook Pro.
La situación es casi la misma que en el caso de R.G, solo que con un portátil de Apple en lugar de uno de HP. El tratamiento de los móviles va a ser exactamente el mismo, así que nos ponemos rápidamente al lío.
 Para este miércoles tenemos una entrada de Antonio Sanz, Ingeniero Superior de Telecomunicaciones y Master en ICT por la Universidad de Zaragoza.
Para este miércoles tenemos una entrada de Antonio Sanz, Ingeniero Superior de Telecomunicaciones y Master en ICT por la Universidad de Zaragoza. 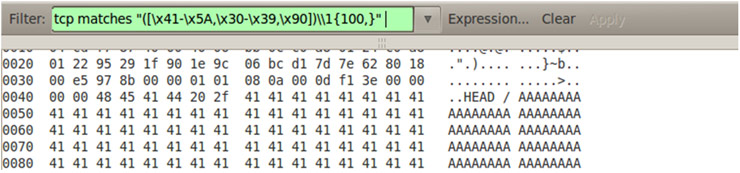
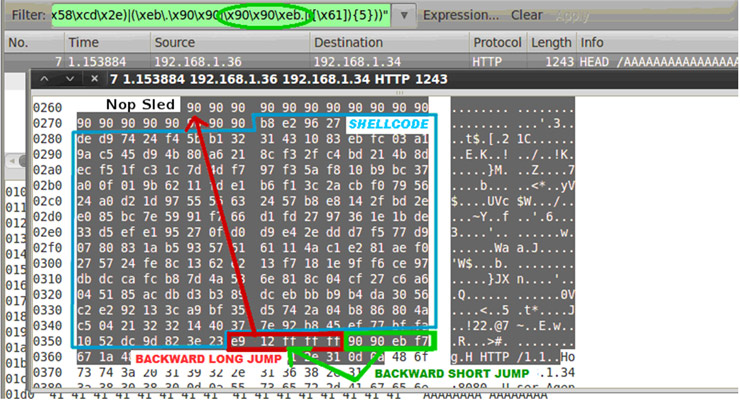
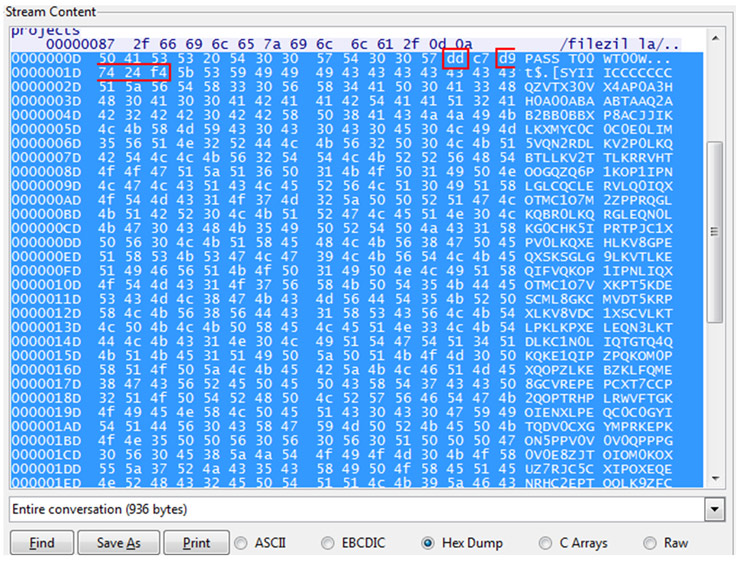
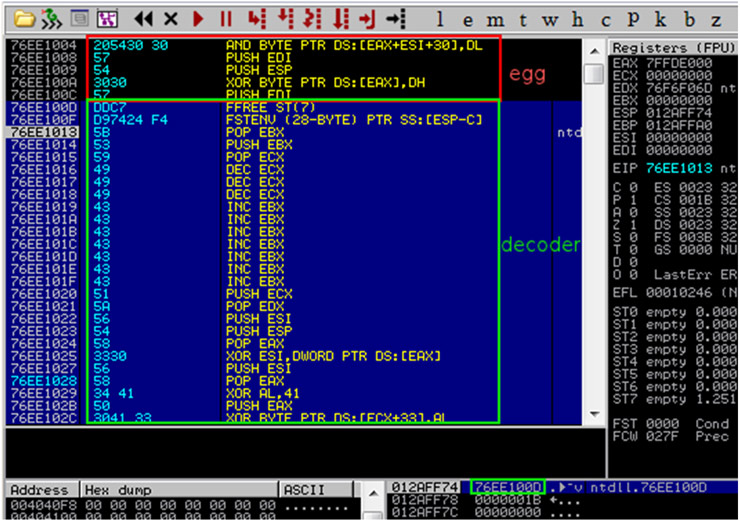
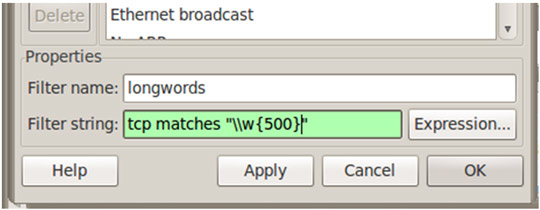
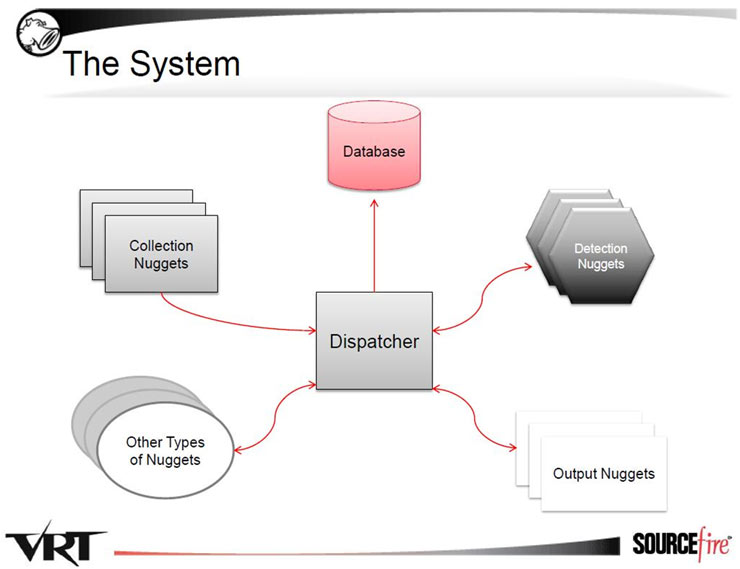
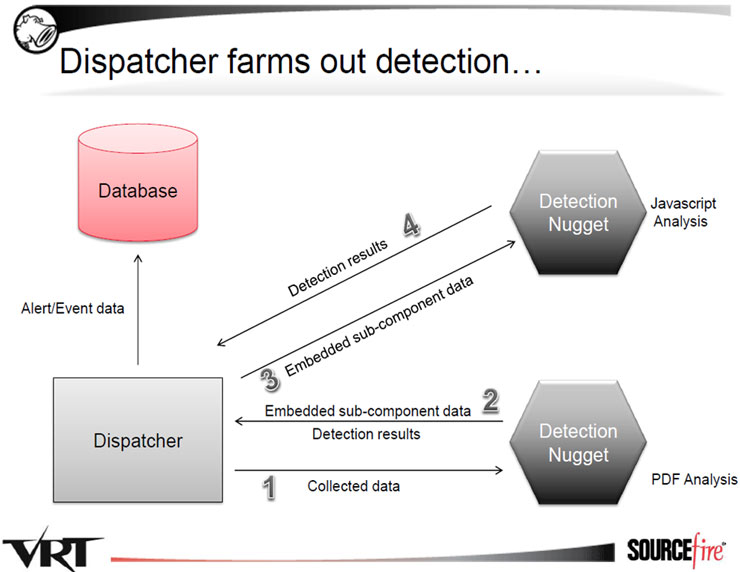
 Recientemente comentábamos entre los compañeros cómo han disminuido, en general, los ataques dirigidos a servidores, aumentando especialmente, por contra, los ataques al usuario. Dichos ataques están siendo cada vez más sofisticados ya que intentan explotar vulnerabilidades muy avanzadas a nivel de cliente, sobretodo a la hora de procesar ficheros “complejos”, como DOC o PDF.
Recientemente comentábamos entre los compañeros cómo han disminuido, en general, los ataques dirigidos a servidores, aumentando especialmente, por contra, los ataques al usuario. Dichos ataques están siendo cada vez más sofisticados ya que intentan explotar vulnerabilidades muy avanzadas a nivel de cliente, sobretodo a la hora de procesar ficheros “complejos”, como DOC o PDF.