
 Son muchas las recomendaciones hechas por ITIL en su Gestión de Incidencias, todas útiles y de implantación obligatoria. Eso sí, ITIL no te las va a resolver, sino que te va a ayudar para establecer un proceso para gestionar cada una de las incidencias, aprender de ellas, ser más proactivos y reactivos, obtener mejoras de cada una de ellas y aplicarlas a la infraestructura IT que se tenga, que no es poco…
Son muchas las recomendaciones hechas por ITIL en su Gestión de Incidencias, todas útiles y de implantación obligatoria. Eso sí, ITIL no te las va a resolver, sino que te va a ayudar para establecer un proceso para gestionar cada una de las incidencias, aprender de ellas, ser más proactivos y reactivos, obtener mejoras de cada una de ellas y aplicarlas a la infraestructura IT que se tenga, que no es poco…
Saber reaccionar ante una incidencia es fundamental, y más aun si conlleva una pérdida de servicio. En este tipo de casos la experiencia es el rasgo más valorado para saber afrontarlas. Por mucha preparación técnica que se tenga, es difícil mantener la compostura y tener la serenidad suficiente para poder abstraerse de la presión y analizar la situación.
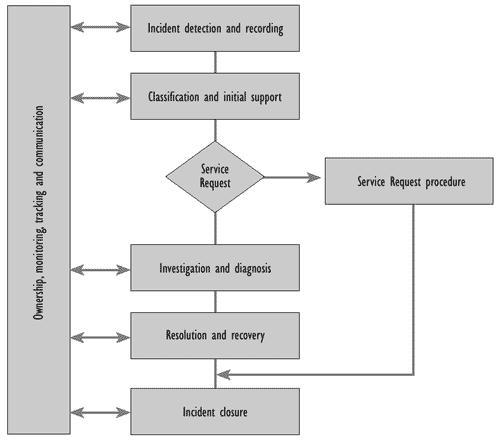
Cierto es que la definición de incidencia se ha convertido en un cajón de sastre, en este término se aglutinan los errores, averías, etc. Es decir, lo primero es saber realmente el tipo de incidencia que lo ha provocado. Algunas recomendaciones de andar por casa, pero basadas en buenas prácticas, podrían ser:
- Mantener la calma. Las prisas son el peor enemigo. La presión es grande, reanudar el servicio es prioritario, pero una acción mal llevada, un comando erróneo, un “Intro” en un momento equivocado nos puede llevar a agravar el problema y entonces lo que podían haber sido diez minutos se convierten en horas.
- Avisar al Service Desk (si lo hay). Es la primera línea de recepción de llamadas, y por tanto tienen que ser los primeros en estar al corriente de lo que está pasando y los servicios afectados.
- Reaccionar. Es importante cualquier alerta. Muchas veces poder reaccionar ante el primer aviso es fácil. Si pensamos que: “ya se solucionará” (cosa que nunca sucede, no me explico la razón…) estamos perdidos. Lo más normal es que el problema se vaya agravando con el paso del tiempo y el sistema se vaya corrompiendo cada vez más.
- Análisis, análisis y analizar. Saber qué es lo que ha ocasionado dicha incidencia puede darnos el camino de cómo solucionarlo. Y si no sabemos la razón, por lo menos analicemos las consecuencias del problema.
- Imagen del estado. Antes de hacer nada, y si se puede, es aconsejable hacer una copia de lo que tenemos en ese momento (si la incidencia es de un servidor). Lo ideal es, si trabajamos en entornos virtuales, hacer un clon de la máquina. Esto nos ayudará de dos maneras diferentes: para poder realizar una vuelta atrás por si acaso deterioramos más que arreglamos y para que, una vez solucionado el problema, poder hacer un análisis forense de dicha máquina.
- Saber si hay copia de seguridad y cuando se hizo. Hay veces que es más rápido y seguro lanzar una restauración de la maquina completa en un sistema replicado, dar servicio, y luego analizar en la original el problema surgido.
Resumiendo, la mejor forma de ser proactivo viene por dos frentes fundamentales: la monitorización y las copias de seguridad. Una buena monitorización, como seguro deben saber, no sólo pasa por comprobar conectividad, sino también servicios, espacio en disco, picos de cpu o memoria… cualquier indicio que nos pueda advertir de un posible problema. Con respecto a lo de las copias, pues no hace falta comentar nada. Tener un backup de unas horas antes de la incidencia es tener asegurada una recuperación del servicio, más pronto o más tarde, pero bajo la serenidad de tener todos los datos a buen recaudo.
Lo que dices de avisar al servidesk es muy importante, yo lo extenderia en avisar a los responsables de negocio afectado, “escalar” la información a niveles superiores para que dispongan de esa información.
El artículo está bien escrito y coincido con el autor en cómo han de hacerse las cosas. Sin embargo no siempre se disponen de los citados recursos… En ocasiones una cadena de fallos puede desencadenar la pérdida total de un servidor y sus servicios.
Totalmente cierto, quietman; hay situaciones imprevisibles en las que no se pueden evitar pérdidas de datos y servicio. Aun así, en esos casos… ante todo mucha calma.
He vivido alguna que otra experiencia que el botonazo de un servidor sin pensarlo dos veces te lleva a un problema mucho más gordo del que estarías si hubieras pensado dos veces posibles alternativas.
Como dice el refrán, vísteme despacio que tengo prisa.