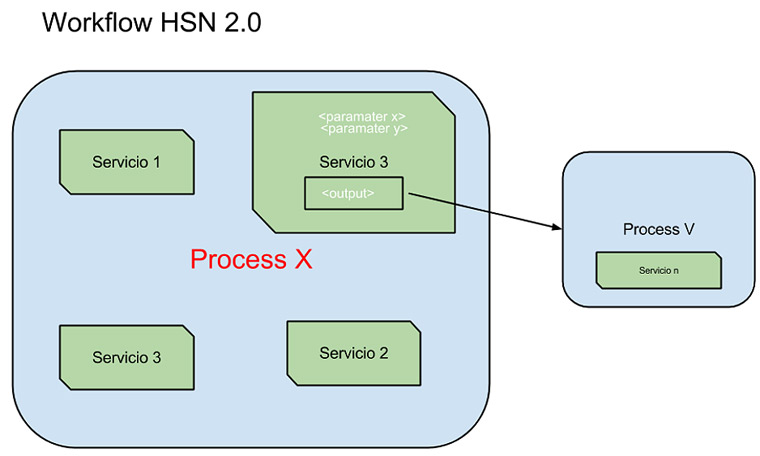
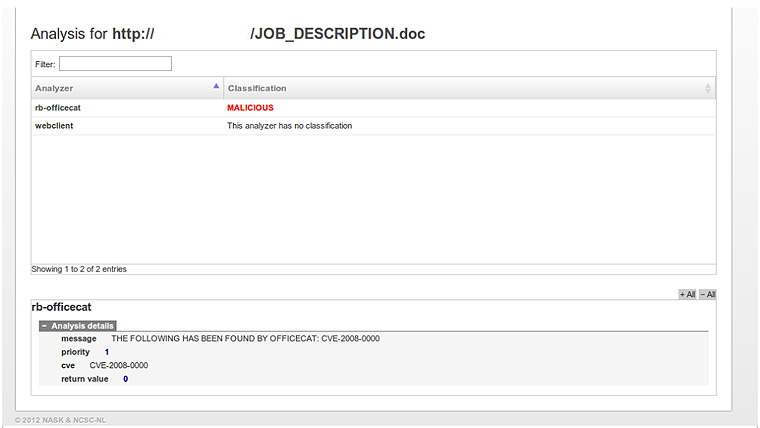
En esta entrada vamos a ver de una manera muy rápida como hacer un análisis de un fichero OLE y analizar los streams que contenga (en este caso se trata de una macro) con la herramienta y reglas de Didier Stevens. El documento no es muy complejo pero nos sirve para ilustrar cómo utilizar esta herramienta.
Hash del fichero cazado en un correo:
e4e46f746fffa613087bba14666a3ceec47e145f Transferencia_Interbancaria.doc
Paso 1: Lanzamos yara con nuestra reglas: