
 Hoy me gustaría compartir con vosotros una aplicación que he descubierto al revisar las ponencias de la próxima RootedCON.
Hoy me gustaría compartir con vosotros una aplicación que he descubierto al revisar las ponencias de la próxima RootedCON.
La herramienta en cuestión es XSSer, un Framework que detecta, explota e informa de vulnerabilidades XSS en aplicaciones Web. Supongo que las vulnerabilidades XSS no son desconocidas para nuestros lectores, aunque si tienen alguna duda pueden visitar esta entrada para refrescar conceptos.
Como comenta el propio autor en la web del proyecto, contiene diversas opciones para evadir ciertos filtros y diferentes técnicas de inyección de código.
Para empezar a usar la herramienta, basta con descargar la última versión del repositorio:
$ svn co https://xsser.svn.sourceforge.net/svnroot/xsser xsser
Una vez realizado esto, podemos ejecutarlo de dos formas distintas, desde consola o mediante su interfaz:
 La entrada de hoy corre a cargo de Javier Cao, un “clásico” del sector que no requiere demasiadas presentaciones y al que nos gustaría ver más a menudo por estos lares.
La entrada de hoy corre a cargo de Javier Cao, un “clásico” del sector que no requiere demasiadas presentaciones y al que nos gustaría ver más a menudo por estos lares.  Una de las tareas comunes que deben aplicarse a un servidor que va a pasar a producción es fortalecer la seguridad que lleva por defecto el sistema. A esto se le llama bastionar o securizar. Como son muchos aspectos los que hay que tener en cuenta para llevar a cabo esta labor, he querido hacer un recopilatorio de las principales tareas de bastionado en Linux.
Una de las tareas comunes que deben aplicarse a un servidor que va a pasar a producción es fortalecer la seguridad que lleva por defecto el sistema. A esto se le llama bastionar o securizar. Como son muchos aspectos los que hay que tener en cuenta para llevar a cabo esta labor, he querido hacer un recopilatorio de las principales tareas de bastionado en Linux. 





 En uno de los últimos portales web que he tenido que desarrollar una de las principales premisas era que tenía que ser muy seguro. El nuevo portal tenía que suplir a una versión hecha en html puro, sin código en el servidor. ¿Para qué cambiar si la versión anterior ya era segura? Tampoco entraré en más detalles pero, ¿os acordáis de esas “bonitas” webs con montones de gifs animados y colores espartanos? Esas páginas eran bonitas al lado de esta. Al grano. Para el desarrollo del nuevo portal se estuvieron haciendo pruebas con varios CMS (Gestores de contenidos) en PHP. ¿Por qué en PHP? Pues porque los recursos del servidor eran limitados, y porque me gusta. Al final nos decantamos por Drupal, ya que ofrecía a priori una robustez y seguridad que otros no. ¡Ah!, y porque me gusta.
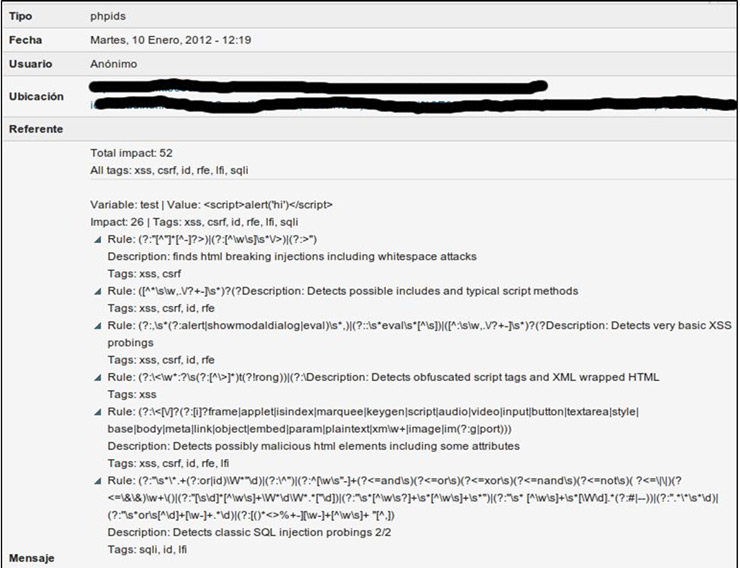
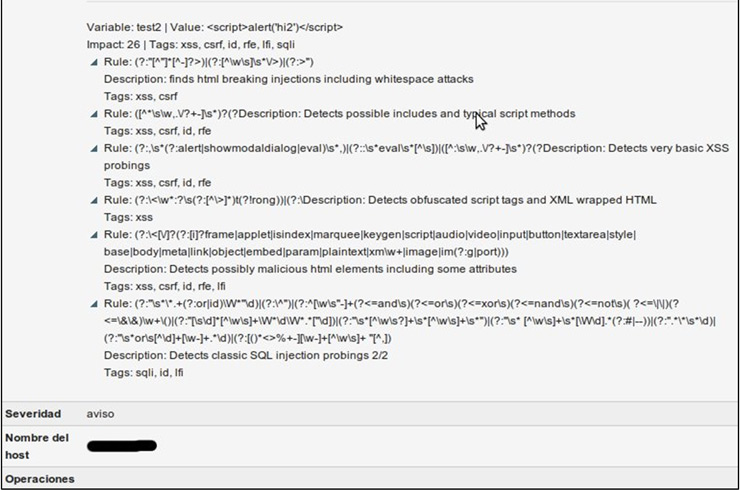
En uno de los últimos portales web que he tenido que desarrollar una de las principales premisas era que tenía que ser muy seguro. El nuevo portal tenía que suplir a una versión hecha en html puro, sin código en el servidor. ¿Para qué cambiar si la versión anterior ya era segura? Tampoco entraré en más detalles pero, ¿os acordáis de esas “bonitas” webs con montones de gifs animados y colores espartanos? Esas páginas eran bonitas al lado de esta. Al grano. Para el desarrollo del nuevo portal se estuvieron haciendo pruebas con varios CMS (Gestores de contenidos) en PHP. ¿Por qué en PHP? Pues porque los recursos del servidor eran limitados, y porque me gusta. Al final nos decantamos por Drupal, ya que ofrecía a priori una robustez y seguridad que otros no. ¡Ah!, y porque me gusta. Otra manera de usar PHPIDS es mediante el módulo de Drupal (ver la
Otra manera de usar PHPIDS es mediante el módulo de Drupal (ver la 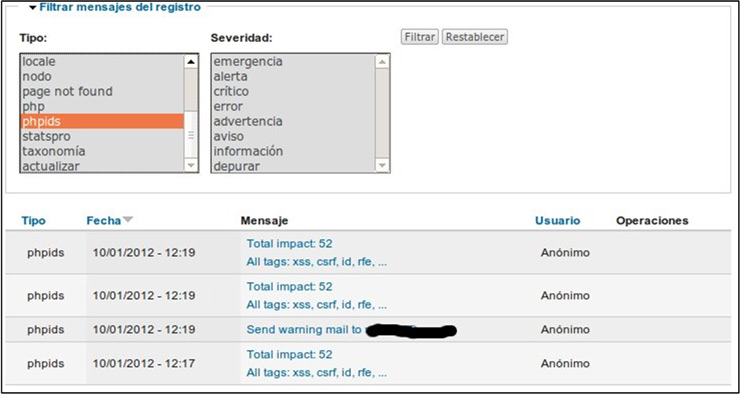

 Es decir, iniciativas que permitan compartir información entre grupos con los mismos intereses o afectados por un problema común. En este caso particular, se pretende fomentar que se compartan experiencias sobre la detección y resolución de vulnerabilidades.
Es decir, iniciativas que permitan compartir información entre grupos con los mismos intereses o afectados por un problema común. En este caso particular, se pretende fomentar que se compartan experiencias sobre la detección y resolución de vulnerabilidades. Estimados lectores, el post de hoy parte del artículo “Privacy and Security, Security Risks in Next-Generation Emergency Services” escrito por Hannes Tschofenig [
Estimados lectores, el post de hoy parte del artículo “Privacy and Security, Security Risks in Next-Generation Emergency Services” escrito por Hannes Tschofenig [