En esta entrada me voy a atrever a darles mi visión personal de las conclusiones que se extrajeron del taller “Gestión de Continuidad: Planes de Contingencia, Gestión de Crisis” del I Encuentro Internacional de Ciberseguridad y Protección de Infraestructuras Críticas, taller que dirigió con mucha habilidad y dinamismo Miguel Rego, Director de Seguridad Corporativa de ONO, y que resultó muy participativo.
En esta entrada me voy a atrever a darles mi visión personal de las conclusiones que se extrajeron del taller “Gestión de Continuidad: Planes de Contingencia, Gestión de Crisis” del I Encuentro Internacional de Ciberseguridad y Protección de Infraestructuras Críticas, taller que dirigió con mucha habilidad y dinamismo Miguel Rego, Director de Seguridad Corporativa de ONO, y que resultó muy participativo.
En el taller personalmente constaté que, salvo honrosas excepciones, muchas de las empresas estratégicas españolas todavía se encuentran en una fase digamos intermedia en cuanto a la implantación real de planes de continuidad de negocio. Todavía se confunden términos, y por ejemplo se establecen equivalencias entre planes de contingencia TIC y planes de continuidad de negocio (si miran la fotografía que acompaña este post estarán de acuerdo conmigo en que “eso” no tiene nada que ver con continuidad TIC). Sobre esto ya les hablé en otro post sobre la resiliencia de las organizaciones.
Se constató el consenso entre los participantes relativo a la necesidad de una mayor sensibilización por parte de los actores, de que falta regulación, y de que faltan estándares en los que basarse que sean realmente de aplicación a sectores tan dispares como el transporte por ferrocarril, la banca o la telefonía móvil. La sensibilidad existente en las IC privadas se basa en la protección del negocio más que en la protección del servicio, y no son aspectos que sean contemplados en las estrategias corporativas. Asimismo, quedó en evidencia la necesidad de que los planes de prueba de los planes de continuidad de negocio consistan en pruebas “de verdad”, y no en simulaciones controladas y poco realistas. También es cierto que la realización de ejercicios de crisis sectoriales realistas es verdaderamente compleja. ¿Deberían ser obligatorias? ¿Y entre sectores interdependientes? ¿Cómo coordinarlas?
Otro de los aspectos que se comentaron fue la necesidad de definir modelos de datos estándar y una interfaz segura para el necesario intercambio de información entre los cuadros de mando y control en la gestión de la continuidad de IC. Se abogó por seguir un modelo como el holandés, en el que el estado “facilita” y apoya y el sector privado lidera y actúa, aunque al final hubo que reconocer que no es un modelo fácilmente implantable en España. Donde surgieron las discrepancias fue a la hora de valorar cuál debería ser el papel del Estado en esta materia. Hubo acuerdo en que debía regular los mínimos exigibles, y en que debía conocer el estado real de la seguridad de las IC nacionales, pero hubo desacuerdo en si además debía revisar, auditar, exigir e incluso sancionar. Por último, se propuso que el Estado subvencionara o apoyara económicamente proyectos I+D+i que trabajaran en esta línea, ayudas quizás dirigidas a asociaciones sectoriales, y se apuntó la idea de que la Responsabilidad Social Corporativa debería ser un impulsor para que las empresas se subieran a este barco.
Además de los temas tratados en el taller, me gustaría añadir algunos otros asuntos vistos durante las dos interesantes jornadas, alguno de los cuales ya ha sido apuntado por José Rosell en el post que escribió sobre este encuentro.
En el apartado de curiosidades o cosas que me llamaron la atención (quizás por ser un neófito en el terreno militar), me llamó la atención la exposición del Teniente Coronel Néstor Ganuza, director de la Sección de Adiestramiento y Doctrina del Centro de Ciberdefensa Cooperativa de la OTAN (aunque independiente de ésta, pues incluso apuntó que el Centro es crítico en algunos temas con la Organización del Tratado del Atlántico Norte), por mostrarse tan abierto a colaborar con otras organizaciones, públicas o privadas. Éste planteó temas interesantes en materia de ciberseguridad: habló de que ya se usan los ciberataques en la defensa de intereses legítimos, e hizo por ejemplo referencia a las declaraciones de Sir Stephen Dalton, jefe del Estado Mayor del Aire de UK, relativas al uso que hace el ejército israelí de twitter.
Como ya he apuntado, me pareció interesante el enfoque holandés presentado por Anne Marie Zielstra, del NICC holandés, basado en la previsión, el trabajo colaborativo entre el sector privado y el público, y dando un carácter básico al intercambio de información entre los dos sectores. Fue también interesante y muy serio el enfoque británico expuesto por Peter Burnett, del OCS (Office of Cyber Security) de UK, que destacó que en los análisis de continuidad de sus ICs están pasando de un enfoque basado en la amenaza a un enfoque basado en el impacto (cuanto mayor pueda ser el impacto, más crítica será la infraestructura), y que corroboró la necesidad de compartir la información para mejorar el conocimiento.
Por último, unas reflexiones personales:
- En España existen unas 3.700 infraestructuras estratégicas (críticas, algunas de ellas), el 80% de las cuales se encuentran en manos privadas.
- Algunos de los ponentes pusieron encima de la mesa la falta de confianza existente a la hora de facilitar información sensible en el necesario intercambio y cooperación entre el sector privado y público ¿a alguien se le escapan los lógicos recelos de, por ejemplo, una telco a la hora de informar de que tiene determinadas carencias de seguridad o de infraestructuras que pueden afectar a su continuidad, recelos que se acentúan si además no tiene la certeza de que esa información no pueda caer en manos de la competencia o de terceros interesados en ver cómo explotar esas vulnerabilidades?
- El Real Decreto de protección de infraestructuras críticas en que se está trabajando es la trasposición de la Directiva Europea 2008/114/CE. Pero cuidado. La directiva europea regula la protección de las ICs de un país que pueden afectar a otros países, pero no entra en el ámbito exclusivamente nacional. Ahí deja el tema a la soberanía y libertad de cada país. Si volvemos a recordar que el 80% de las infraestructuras estratégicas españolas está en manos privadas, y les comento que durante las jornadas la frase que todos los representantes de ICs nacionales privadas pronunciaron fue “¿Y esto quién lo paga?”, tenemos como país un importante reto por delante.
Todo esto, mientras estos días más de 100.000 personas de la Costa Brava gerundense han pasado (y algunos siguen pasando) varios días sin suministro eléctrico, 40.000 sin teléfono fijo y sólo un 50% de cobertura de telefonía móvil tras la nevada de hace unos días.
Vamos, que ni al pelo para el post.
 Estimados lectores, muy frecuentemente el primer pensamiento por parte de las empresas a la hora de afrontar la seguridad viene marcado por fuertes inversiones, como pueden ser costosas soluciones en infraestructura de red (IDS, Firewall), la compra de antivirus centralizados, suites de ServiceDesk, o laboriosos proyectos de consultoría. Si bien acometer dichas proyectos o compras de este tipo es un requisito para la consecución de cierto grado de seguridad empresarial, no resulta ser la panacea a la totalidad de los problemas de seguridad.
Estimados lectores, muy frecuentemente el primer pensamiento por parte de las empresas a la hora de afrontar la seguridad viene marcado por fuertes inversiones, como pueden ser costosas soluciones en infraestructura de red (IDS, Firewall), la compra de antivirus centralizados, suites de ServiceDesk, o laboriosos proyectos de consultoría. Si bien acometer dichas proyectos o compras de este tipo es un requisito para la consecución de cierto grado de seguridad empresarial, no resulta ser la panacea a la totalidad de los problemas de seguridad. Esta, entre otras, es una eterna cuestión que rodea a los datos personales y que nos da más de un dolor de cabeza: ¿es la IP un dato de carácter personal? Pues bien, todo parece apuntar, según lo que les mostraré en esta entrada, que sí. Yo, si les digo la verdad, siempre he sido un poco reacio a considerarla como tal, al menos en algunos ámbitos. Veamos un par de definiciones del Reglamento de Desarrollo de la LOPD:
Esta, entre otras, es una eterna cuestión que rodea a los datos personales y que nos da más de un dolor de cabeza: ¿es la IP un dato de carácter personal? Pues bien, todo parece apuntar, según lo que les mostraré en esta entrada, que sí. Yo, si les digo la verdad, siempre he sido un poco reacio a considerarla como tal, al menos en algunos ámbitos. Veamos un par de definiciones del Reglamento de Desarrollo de la LOPD: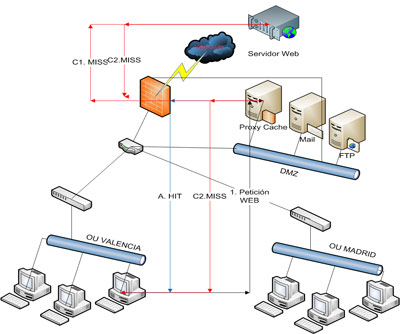 Como puede verse, en el mejor de los casos nos ahorramos el enrutamiento desde el proxy al servidor sobre el que se realiza la petición y la transferencia de la información solicitada a través de Internet, mientras que en el peor de los casos añadimos un salto más en el enrutamiento. Por supuesto, cuánto más accedido sea un determinado contenido por los usuarios de la red interna, mayor probabilidad de que el objeto se encuentre en cache y por tanto, mayor incremento del rendimiento del sistema.
Como puede verse, en el mejor de los casos nos ahorramos el enrutamiento desde el proxy al servidor sobre el que se realiza la petición y la transferencia de la información solicitada a través de Internet, mientras que en el peor de los casos añadimos un salto más en el enrutamiento. Por supuesto, cuánto más accedido sea un determinado contenido por los usuarios de la red interna, mayor probabilidad de que el objeto se encuentre en cache y por tanto, mayor incremento del rendimiento del sistema. Hace un par de semanas tuvo lugar en Madrid
Hace un par de semanas tuvo lugar en Madrid  Hace ya unos meses, en este mismo
Hace ya unos meses, en este mismo