
 – Con este post me gustaría inaugurar una nueva sección en SAW llamada Barbarities, destinada a albergar cual pozo ciego, todas aquellas atrocidades que desde el punto de vista de seguridad uno ha ido viendo con el paso de los años. Se anima al lector a que comparta sus experiencias –
– Con este post me gustaría inaugurar una nueva sección en SAW llamada Barbarities, destinada a albergar cual pozo ciego, todas aquellas atrocidades que desde el punto de vista de seguridad uno ha ido viendo con el paso de los años. Se anima al lector a que comparta sus experiencias –
Barbarities… Hoy: La banca electrónica.
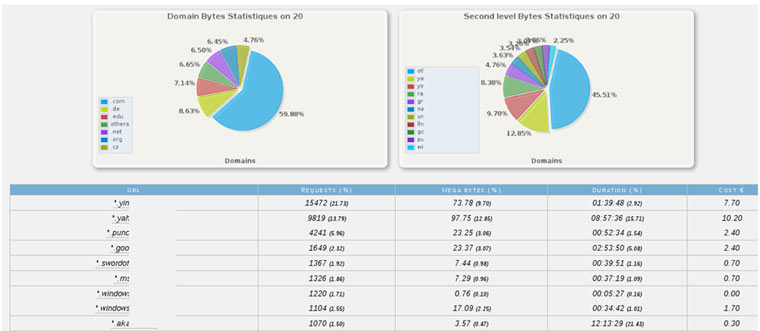
Los bancos, dentro de lo que cabe, hacen un esfuerzo por entregar a sus clientes medidas de protección ante el fraude y robo online a la hora de operar a través de sus páginas web o apps móviles. Códigos de validación de transacción por SMS, uso de https (qué menos…), teclados virtuales anti Click-hacking o tarjetas de coordenadas son solo algunos ejemplos de estas protecciones.
 Como era de esperar, en el MWC de Barcelona se han presentado multitud de novedades en el mundo de la tecnología móvil, principalmente. Sin embargo, eventos previos a la apertura del MWC hay otros como es el MobileFocus. No voy a hablar de las últimas novedades de Samsung. Aquí el protagonista es… ¡AVG! Sí, sí, has leído bien, AVG. La compañía antivirus y su departamento de Innovación ha presentado en el MobileFocus unas gafas que te hacen invisible.
Como era de esperar, en el MWC de Barcelona se han presentado multitud de novedades en el mundo de la tecnología móvil, principalmente. Sin embargo, eventos previos a la apertura del MWC hay otros como es el MobileFocus. No voy a hablar de las últimas novedades de Samsung. Aquí el protagonista es… ¡AVG! Sí, sí, has leído bien, AVG. La compañía antivirus y su departamento de Innovación ha presentado en el MobileFocus unas gafas que te hacen invisible. Básicamente permite que, a la persona que lleva estas gafas, no se le pueda identificar mediante cámaras y otros sistemas de reconocimiento facial. Bueno, a quien se anime a llevarlas… más que nada porque son un poco feas. Pero, dejando de lado los aspectos estéticos, ¿cómo funcionan? Tal y como explica AVG funcionan gracias a dos principales materiales utilizados para su fabricación.
Básicamente permite que, a la persona que lleva estas gafas, no se le pueda identificar mediante cámaras y otros sistemas de reconocimiento facial. Bueno, a quien se anime a llevarlas… más que nada porque son un poco feas. Pero, dejando de lado los aspectos estéticos, ¿cómo funcionan? Tal y como explica AVG funcionan gracias a dos principales materiales utilizados para su fabricación.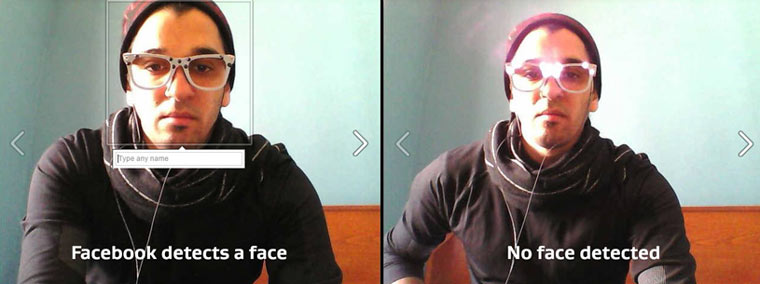

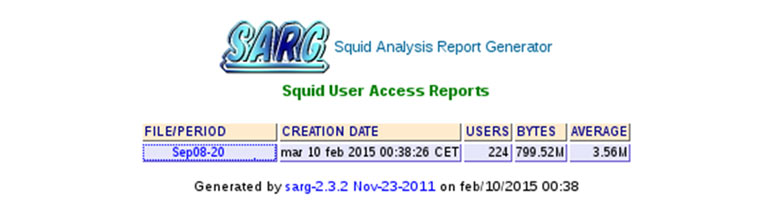
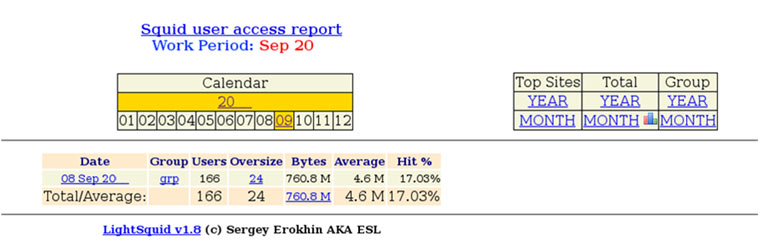
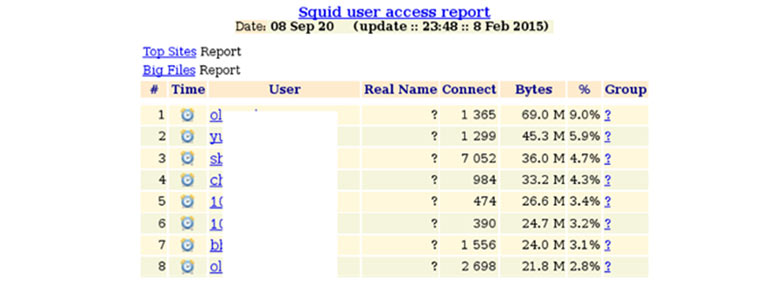

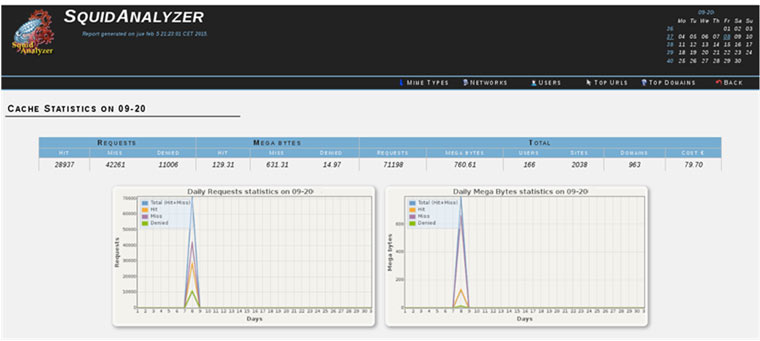
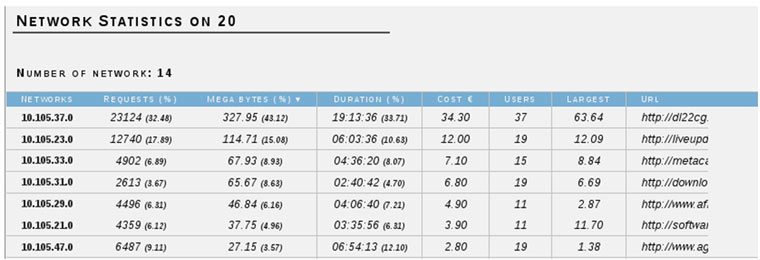
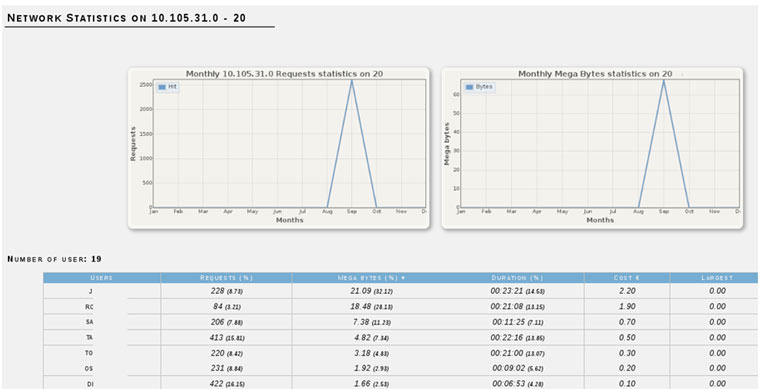

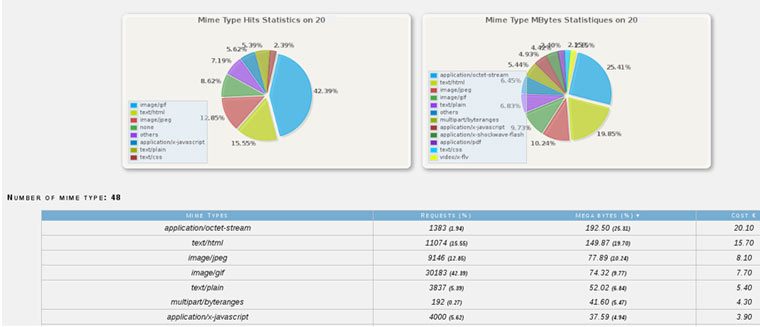
 Hace unos meses, llegó a España la aplicación
Hace unos meses, llegó a España la aplicación 




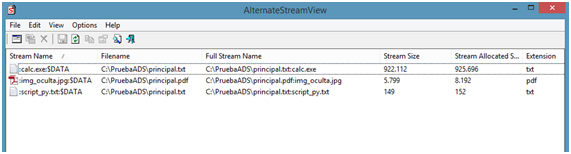
 Existen ideas que se resisten a desaparecer. Y entre ellas hay un tipo especial, las que se basan en la confusión entre los propios deseos y la realidad. En ocasiones estas ideas se convierten en entes que sobreviven a su propia refutación. Durante siglos el ser humano ha ambicionado construir una máquina que sea capaz de funcionar continuamente, produciendo trabajo y sin aportes energéticos del exterior. Tanto la ha buscado que tiene hasta nombre: el móvil perpetuo de primera especie.
Existen ideas que se resisten a desaparecer. Y entre ellas hay un tipo especial, las que se basan en la confusión entre los propios deseos y la realidad. En ocasiones estas ideas se convierten en entes que sobreviven a su propia refutación. Durante siglos el ser humano ha ambicionado construir una máquina que sea capaz de funcionar continuamente, produciendo trabajo y sin aportes energéticos del exterior. Tanto la ha buscado que tiene hasta nombre: el móvil perpetuo de primera especie.