En una auditoría que llevamos a cabo recientemente, surgió la necesidad de inspeccionar el contenido de ciertos ficheros en formato binario, que a todas luces se trataba de objetos Java serializados:
$ file serialized.bin serialized.bin: Java serialization data, version 5
En efecto, los dos primeros bytes eran el magic number de este tipo de ficheros:
0000000 edac 0500 ... 0000010 ... 0000020 ... 0000030 ... 0000040 ...
pero los objetos serializados debían ser relativamente complejos, por lo que un mero strings sobre el fichero no nos ayudaba a “descifrar” la información.
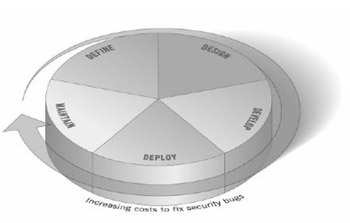 No es un secreto para nadie que una parte importante de los problemas de seguridad de los sistemas de información tiene su origen en defectos de las aplicaciones que éstos ejecutan. Tampoco lo es que estos defectos, que se manifiestan en forma de vulnerabilidades, se introducen en el software durante su proceso de desarrollo. Lo que a día de hoy no es algo aún suficientemente conocido, es la solución a este problema.
No es un secreto para nadie que una parte importante de los problemas de seguridad de los sistemas de información tiene su origen en defectos de las aplicaciones que éstos ejecutan. Tampoco lo es que estos defectos, que se manifiestan en forma de vulnerabilidades, se introducen en el software durante su proceso de desarrollo. Lo que a día de hoy no es algo aún suficientemente conocido, es la solución a este problema.  Como todos los veranos, este año se ha celebrado la
Como todos los veranos, este año se ha celebrado la