
Ahora que la W3C y el IETF están cerrando la normalización de toda la implementación de websockets, no cabe duda de que el futuro RFC6455 está siendo cada vez más utilizado en multitud de plataformas donde la experiencia de usuario es un plus más sobre su oferta de servicios.
El protocolo implementado ya en todos los navegadores permite unas nuevas líneas de comunicación cliente-servidor bidireccionales que desde el punto de vista de la seguridad se deben tener en cuenta. Además, desde la administración de sistemas (que es lo que toco), sí existe la responsabilidad de diseñar una buena arquitectura que ayude a la seguridad de todo el conjunto aunque al final uno queda a merced del buen código del propio desarrollo.
Mirando desde el lado del cliente ya existen en la red ciertos documentos (véase Shekyan Toukharian – Hacking Websocket Slides) de cómo cualquier ejecución no autorizada sobre protocolos embebidos en el navegador, como puede ser javascript, pueden lanzar comunicaciones que vayan por estos canales bidireccionales que proporciona los websockets en background. Todo ello sin el conocimiento del usuario.
Por otro lado, desde el punto de vista del servidor, la perspectiva puede ser otra.
Como la comunicación entre el cliente (navegador) y el servidor es necesariamente directa para mantener esos canales, ciertas instalaciones acaban exponiendo sus servidores sobre los que se soportan los websockets. Realmente esto no sería mayor problema si se realizase correctamente pero sí que lo puede ser cuando dicha exposición, para permitir la comunicación, conlleva que el backend quede alcanzado desde fuera para que los navegadores, y desde ese momento todo Internet, puedan acceder a él.

Los inconvenientes son dos muy claros:
- No es posible la aplicación eficiente de reglas cuando son los navegadores de móviles, navegadores de portátiles y n-mil dispositivos de internet los que tienen que acceder al server vía websockets.
- Multitud de servidores necesitan de extensiones no instaladas en los ISPs para su uso.
La conclusión de estos inconvenientes es que en ocasiones se opta por la exposición directa del backend como ya comentábamos (o la no implementación de websockets, con la renuncia evidente a sus características). Sin embargo, hay multitud de LB (loadbalancers) que SÍ soportan websockets: haproxy, nginx desde hace poquillo, varnish…. y también los hay que hasta la fecha usaban implementaciones más controvertidas: apache con mod_pywebsocket, que no obstante, no es de todos los gustos.
Realmente hay cientos de arquitecturas pero para hoy vamos a elegir como ejemplo Nginx con Node.js y Sockect.io.
Las implementaciones de Socket.io son sencillas. Es autocontenido y el trabajo con sockets del propio Socket.io permite que se pueda optar por un acceso directo contra el puerto del Node.js. No obstante, si el despliegue de Node.js lo hacemos desde el backend (por un tema de intercomunicación y escalabilidad) exponemos un servicio que tal vez no era necesario. La alternativa tal vez podría ser optar por “encapsular”, y por tanto abstraer el acceso al Node.js a través de un segundo dominio y gracias a un nginx por ejemplo.
Nginx nos permite también una exquisita creación de hilos en caso de picos y nos proporciona un buen nivel de abstracción para websockets desde su versión 1.3.x (que no recomiendo porque anda con algún importante bug de seguridad). Así que nos metemos en la 1.4.1 ya que las versiones anteriores no soportan estas comunicaciones.

El proceso es sencillo. Únicamente vamos a necesitar un nombre de dominio adicional a nuestra config (si ya hubiera una). Esto nos permite de forma muy sencilla desmarcarnos del resto de funciones que esté realizando nginx (web, vídeo, etc etc) y usar la funcionalidad de websockets únicamente para ese nombre de dominio (servers en nginx).
Tenemos que crear un upstream para el control de los backends y creamos sock.midominio.es
Al final la implementación sería algo como:
upstream websockets_nodejs {
server backend:9090;
}
server {
listen 80;
server_name sock.midominio.es;
root /usr/local/app/sock/app/webroot;
keepalive_timeout 512;
location / {
proxy_pass http://websockets_nodejs;
proxy_redirect off;
proxy_http_version 1.1;
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
}
Varias anotaciones:
- server backend:9090: backend es un nombre de /etc/hosts y 9090 es el puerto por defecto donde se levanta nodejs.
- keepalive_timeout: mejor corto que largo por tema de recursos pero si el código no es capaz de controlar la conexión es posible indicar un número superior para evitar algunos comportamientos anómalos.
- El resto de líneas son de manual. Únicamente faltaría indicar en nuestro desarrollo como acceder al server que gestiona los websockets indicando nuestro nuevo dominio y si, todo por el puerto 80.
Con esto acabamos de incorporar un nivel de abstracción más sobre nuestra arquitectura delegando al buen hacer de nginx el control y gestión de las conexiones contra el backend Node.js+Socket.io.
Evidentemente es posible configurarlo sobre SSL sin problemas:
upstream websockets_nodejs {
server backend:9090;
}
server {
listen 443;
server_name sckts.midominio.es;
root /usr/local/app/sock/app/webroot;
index index.php;
keepalive_timeout 512;
ssl on;
ssl_certificate /etc/nginx/server.crt;
ssl_certificate_key /etc/nginx/server.key;
ssl_session_timeout 5m;
ssl_protocols SSLv2 SSLv3 TLSv1;
ssl_ciphers ALL:!ADH:!EXPORT56:RC4+RSA:+HIGH:+MEDIUM:+LOW:+SSLv2:+EXP;
ssl_prefer_server_ciphers on;
location / {
proxy_pass http://websockets_nodejs;
proxy_redirect off;
proxy_http_version 1.1;
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
}
Ahora en la configuración de vuestro desarrollo deberéis conectar sobre https.
En nuestro entorno de pruebas ha ido de maravilla aunque siempre habrá alguien que podrá apuntar más datos interesantes sobre estas arquitecturas. En ese caso, bienvenido sea.


 Pero ahora que estoy rodeada de gente que sabe de seguridad y se preocupa por la privacidad, estoy empezando a plantearme cosas a las que antes no les daba
Pero ahora que estoy rodeada de gente que sabe de seguridad y se preocupa por la privacidad, estoy empezando a plantearme cosas a las que antes no les daba 



 Security Art Work comenzó hace poco más de seis años por iniciativa del que escribe estas palabras, lo que hace que le tenga un especial cariño. Como sabrán, una de las políticas no escritas de Security Art Work siempre ha sido la ausencia de publicidad propia o ajena; Security Art Work fue creado para compartir conocimiento, no como una plataforma para hacer publicidad.
Security Art Work comenzó hace poco más de seis años por iniciativa del que escribe estas palabras, lo que hace que le tenga un especial cariño. Como sabrán, una de las políticas no escritas de Security Art Work siempre ha sido la ausencia de publicidad propia o ajena; Security Art Work fue creado para compartir conocimiento, no como una plataforma para hacer publicidad. 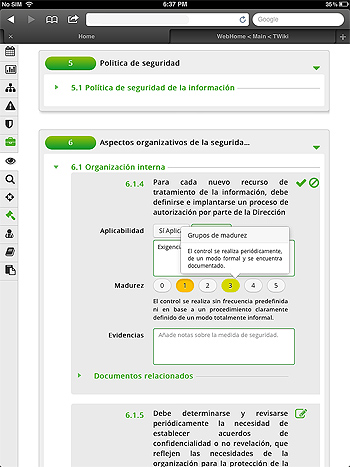 Hace aproximadamente un año, comencé a trabajar en una herramienta que mejorase la implantación y mantenimiento de un SGSI y diese respuesta a diversos problemas a los que en el pasado me he tenido que enfrentar. Esta idea inicial creció y con esfuerzo ha acabado convirtiéndose en una realidad, lo que nos lleva de nuevo hasta el día de hoy. Me siento especialmente orgulloso de presentar tiké® en público: la herramienta de S2 Grupo para la gestión de referentes normativos y legales. No sólo por mi papel en su nacimiento o como responsable funcional, sino sobre todo por todo el trabajo que nos ha costado llegar hasta aquí y que no me cabe duda de que ha valido la pena.
Hace aproximadamente un año, comencé a trabajar en una herramienta que mejorase la implantación y mantenimiento de un SGSI y diese respuesta a diversos problemas a los que en el pasado me he tenido que enfrentar. Esta idea inicial creció y con esfuerzo ha acabado convirtiéndose en una realidad, lo que nos lleva de nuevo hasta el día de hoy. Me siento especialmente orgulloso de presentar tiké® en público: la herramienta de S2 Grupo para la gestión de referentes normativos y legales. No sólo por mi papel en su nacimiento o como responsable funcional, sino sobre todo por todo el trabajo que nos ha costado llegar hasta aquí y que no me cabe duda de que ha valido la pena.