
 Aún recuerdo cuando empecé a introducirme en el mundo de la auditoría y seguridad allá por el año 2001, en una asignatura de la universidad, con un profesor que daba una asignatura enfocada a la gestión de empresas, y pensé este hombre habla de cosas interesantes y no de teoremas y algoritmos que probablemente no emplearé en esta vida. A partir de ese momento comencé a asistir a charlas en las que me dejaba impresionar por la corbata y la dialéctica de los ponentes y asistentes que disponían de sabiduría sobre todos los campos de la materia. Ya sabéis: corbatas, trajes, y retórica (nada nuevo bajo el sol).
Aún recuerdo cuando empecé a introducirme en el mundo de la auditoría y seguridad allá por el año 2001, en una asignatura de la universidad, con un profesor que daba una asignatura enfocada a la gestión de empresas, y pensé este hombre habla de cosas interesantes y no de teoremas y algoritmos que probablemente no emplearé en esta vida. A partir de ese momento comencé a asistir a charlas en las que me dejaba impresionar por la corbata y la dialéctica de los ponentes y asistentes que disponían de sabiduría sobre todos los campos de la materia. Ya sabéis: corbatas, trajes, y retórica (nada nuevo bajo el sol).
Pensaréis que a qué viene todo esto. Pues bien, hubo un momento a partir del cual me di cuenta de que no era oro todo lo que relucía; que no todos los profesionales del sector eran eruditos de las tecnologías ni expertos en todos los campos de la informática. Lo recuerdo como si fuera ayer. Estaba una charla en la que se hablaban de subvenciones relacionadas con proyectos tecnológicos, y en un momento se produjo una discusión sobre LOPD entre dos personas. Uno de ellos dijo que su formación universitaria provenía de un campo diametralmente opuesto a las ingenierías, aunque defendía vehemente sus ideas en cuanto a LOPD. En ese momento me pregunte a mí mismo si mi vecino el charcutero podría firmar un informe de auditoría del RDLOPD.
Releyendo la LOPD obtuve la respuesta, que se imaginarán: efectivamente, mi vecino el charcutero podría firmar auditorías del RDLOPD, lo que más adelante tuve ocasión de confirmar en una charla de la propia Agencia de Protección de datos a la que asistí. Una de las transparencias exponía lo siguiente:
- ¿La auditoría es LOPD? ¿quién debe realizarla? ¿debe notificarse?
- No se define o reconoce el perfil funcional o profesional de los auditores
Resulta curioso que el charcutero pueda firmar auditorias LOPD pero no pueda hacer la prevención de riesgos laborales. Pasado el tiempo podemos llegar a aceptar que esto sea así, pero cual fue mi sorpresa cuando el otro día acabe con el libro de mesita de cama y empecé con el borrador del Esquema Nacional de Seguridad (véase I, II y III) y no encontré ningún requisito para el auditor, más que lo siguiente:
Lo que me hace pensar en la necesidad imperante de subsanar estos “vacíos legales” por el órgano pertinente. Reflexionando sobre esto, me queda claro que no es un asunto trivial, y que realmente si no se ha especificado más detalladamente el perfil del auditor, es por la problemática asociada: ¿a qué colectivos favorecemos y a qué colectivos dejamos fuera? Lo que está claro es que no va a llover a gusto de todos.
No dispongo de cifras pero estamos hablando de algo más que un puñado de millones de euros, y como todos sabréis, todos quieren su parte del pastel, lo que supone un claro conflicto de intereses.
¿Cómo y a quien otorgar la calificación de auditor?
En una de las últimas jornadas que asistí, este fue uno de los temas a tratar y se comentó tangencialmente la creación de asociaciones privadas “sin ánimo de lucro” tanto en el ámbito LOPD como el de la seguridad, que tuvieran el privilegio de nominar auditores a golpe de varita mágica; la existencia de una Sociedad General de Auditores, una especie de SGAE II, me pone los pelos como escarpias de solo pensarlo. Imaginen la cúpula de esa asociación, formada por los directores mejores relacionados de las auditoras y consultoras más influyentes, limitando únicamente la ejecución de auditorías a sus empresas… oligopolio es la palabra que me viene a la cabeza, y no exagero un ápice.
Descartemos este acercamiento al problema por “mercado de libre competencia”, y ataquemos el asunto de los auditores por la vertiente de la formación. Tras examinar el Esquema Nacional de Seguridad, se observa que éste aboga por una vertiente puramente técnica, al contrario que la LOPD, donde se considera de facto la presencia de un abogado en la auditoria, y la figura técnica queda difusa pudiendo ser realizada por cualquier “técnico”.
Por tanto partamos de la hipótesis de que el auditor debe ser ingeniero, pero vamos a hilar más fino. Cojamos un punto del esquema, “4.2 Control de accesos” y veamos qué ingenierías dan formación específica en este punto. Obviamente en Industriales la materia más difícil es “configura tus servidor radius para autenticación remota”, y en telecomunicaciones donde el primer año te explican cómo configurar LDAP para integrarlo con el dominio…
¿Se os ocurre qué ingeniería debería ocupar ese puesto? Una vez más la ingeniería más agraviada, la única que no dispone de atribuciones.
Pero aceptemos que una ingeniería de carácter técnico pueda acometer estos proyectos, y limitamos el agravio comparativo. Pensemos en el futuro en el plan Bolonia, aceptemos los estudios de grado. Llegados a este punto es posible que se cumplan los requisitos y no se dispongan de las destrezas necesarias; ¿cómo damos esas destrezas a las personas?
Una propuesta que se me ocurre sería la creación de un postgrado oficial en seguridad de la información, reconocido por el estado e impartido por universidades públicas, que sería convalidable por aquel titulado universitario que pudiera acreditar X años de experiencia en el sector y los méritos apropiados. Pero queda claro que únicamente el personal cualificado debería acometer este tipo de proyectos y mientras esto no sea así, seguiremos asociando la profesión del consultor de seguridad a la venta de humo.
¿Están ustedes de acuerdo? ¿Qué opinan al respecto y qué alternativas se les ocurren?
 (N.d.E. Durante el fin de semana hemos estado haciendo algunos cambios en el blog, para lo que tuvimos que desactivar algunas funcionalidades. En cualquier caso, ahora todo debería funcionar correctamente)
(N.d.E. Durante el fin de semana hemos estado haciendo algunos cambios en el blog, para lo que tuvimos que desactivar algunas funcionalidades. En cualquier caso, ahora todo debería funcionar correctamente)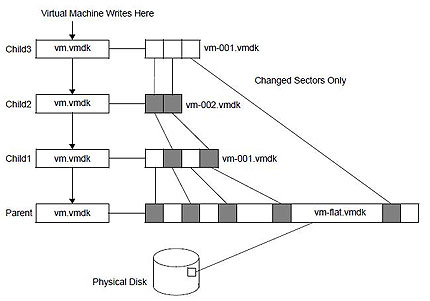 Otra cuestión a tomar en cuenta es la generación de snapshots sobre snapshots. Me explico con un ejemplo: antes de una intervención hemos generado un snapshot, todo ha ido bien, pero no lo borramos “por si acaso”. Al poco tiempo tenemos otra intervención en el mismo servidor, y generamos de nuevo otro snapshot. Esto es totalmente posible y se hace habitualmente, pero no creo que sea una práctica recomendable. El resultado es que se van generando “discos hijos”, cada uno con sus puntos de cambios, y al final el disco virtual inicial acaba siendo una segregación de ficheros, los cuales en caso de error son mucho más complicados de tratar. Personalmente, después de una intervención tras comprobar que todo ha ido bien siempre consolido los snapshots, con lo cual se vuelven a fundir los discos en uno sólo. Tal vez el gráfico que se muestra (fuente
Otra cuestión a tomar en cuenta es la generación de snapshots sobre snapshots. Me explico con un ejemplo: antes de una intervención hemos generado un snapshot, todo ha ido bien, pero no lo borramos “por si acaso”. Al poco tiempo tenemos otra intervención en el mismo servidor, y generamos de nuevo otro snapshot. Esto es totalmente posible y se hace habitualmente, pero no creo que sea una práctica recomendable. El resultado es que se van generando “discos hijos”, cada uno con sus puntos de cambios, y al final el disco virtual inicial acaba siendo una segregación de ficheros, los cuales en caso de error son mucho más complicados de tratar. Personalmente, después de una intervención tras comprobar que todo ha ido bien siempre consolido los snapshots, con lo cual se vuelven a fundir los discos en uno sólo. Tal vez el gráfico que se muestra (fuente  Una de las mejores definiciones que he leído de Seguridad es aquella que dice que la Seguridad es una sensación. Las personas tenemos la sensación de estar seguras o inseguras en base percepciones, estímulos que recibimos del entorno y que nos hacen sentirnos de esa manera.
Una de las mejores definiciones que he leído de Seguridad es aquella que dice que la Seguridad es una sensación. Las personas tenemos la sensación de estar seguras o inseguras en base percepciones, estímulos que recibimos del entorno y que nos hacen sentirnos de esa manera.