
Hace ya algunos meses del primer y segundo artículo de “Bichos et al” en los que comentábamos la posibilidad de desarrollar sin demasiadas complicaciones software malicioso indetectable por los sistemas antivirus. Durante este tiempo, he intentado dedicar tiempo a realizar una pequeña prueba de concepto y a realizar diversas pruebas con diferentes sistemas antivirus para demostrar que es posible burlarlos siguiendo las pautas que se mencionaron en el apartado anterior.
Sin embargo, no llegué a terminar dicha prueba de concepto, puesto que en el proceso de documentación descubrí el troyano RaDa, desarrollado por Raúl Siles, David Pérez y Jorge Ortiz, que demuestra exactamente lo mismo que se pretendía en este artículo, y siguiendo una filosofía muy cercana a la aquí planteada.
Dicho troyano camufla su tráfico encapsulando a través del protocolo HTTP o HTTPS, haciéndolo por tanto indistinguible para cualquiera (incluyendo un sistema de detección de intrusiones) de un acceso web legítimo. Dicho trabajo fue publicado como reto como parte del Honeynet Project y, tal y como mencionaron sus autores en el documento de solución de dicho reto [PDF], hasta el momento de ser publicado en la web ningún sistema antivirus había sido capaz de detectarlo, con lo que vemos un claro ejemplo de la limitación de la detección basada en firmas: software malicioso nuevo, del que no existen firmas.
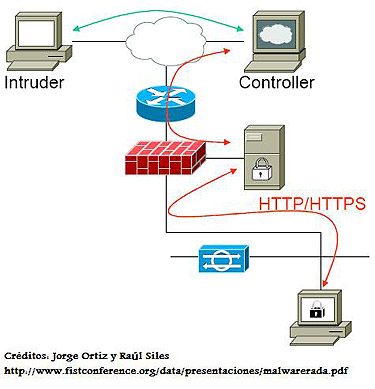
Imaginemos que en lugar de publicar el código para ser analizado, los autores lo hubieran utilizado para infectar determinados equipos que resultaran de su interés. El resultado hubiera sido que los sistemas infectados, a pesar de tener un sistema antivirus perfectamente configurado y actualizado, no hubieran sido capaces de detectar la infección, quedando todos los datos a disposición del atacante.
Como parte del reto del Honeynet Proyect se instaba a los participantes a desarrollar una firma para la detección de este troyano por medio del tráfico que genera. Evidentemente, por tratarse este desarrollo de una prueba de concepto, los desarrolladores tampoco pusieron especial enfasis en ocultar la comunicación más allá que utilizando el protocolo HTTP (y sin ponerle ese énfasis que sin duda un atacante malicioso habría puesto, consiguieron su objetivo, demostrando la ineficacia de los sistemas antivirus), y los comandos intercambiados se transmitían en texto plano. En caso de que un administrador detectara alguna anomalía y visitara la web, vería claramente que no se trata de una web corriente. Pero, si en lugar de emplear este sistema —más que suficiente para lograr el objetivo que se perseguía— la comunicación hubiera sido cifrada, ocultada dentro de algún nombre de imagen o de algún parámetro “ALT” dentro del tag HTML “img”, o se hubiera empleado algún método alternativo para esconder el propósito malicioso de la web, el resultado hubiera sido completamente diferente. Finalmente, los autores también hacen referencia a la posibilidad de utilizar otro tipo de protocolos para la ocultación de este tipo de tráfico como puedan ser el tráfico ICMP, el correo, DNS, etc.; les recomiendo fervientemente la lectura del citado artículo.
Para acabar, ¿quiere decir esto que no podemos hacer nada para evitar ser infectados? Pues ni sí, ni no. S�? podemos, pero NO confiando únicamente en los antivirus. Éstos no son sino otra herramienta más que nos ayuda a mejorar nuestro nivel de seguridad, que puede resultar eficaz para la detección y eliminación de virus de difusión amplia —que representan a fin de cuentas la inmensa mayoría de los que nos vamos a encontrar—, pero en la que no podemos delegar toda nuestra seguridad.
El lunes, en la próxima y última entrega de esta serie veremos varios consejos que pueden ayudarnos a reducir los riesgos de esta naturaleza. Como siempre, pasen un buen fin de semana.
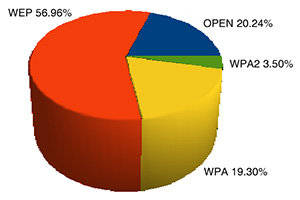 El gráfico de la izquierda establece el porcentaje de uso de cada protocolo obtenido de una muestra de 2658 puntos de acceso tomada en el escenario de pruebas, con la siguiente distribución:
El gráfico de la izquierda establece el porcentaje de uso de cada protocolo obtenido de una muestra de 2658 puntos de acceso tomada en el escenario de pruebas, con la siguiente distribución: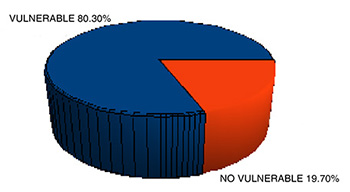
 La solución a este problema puede encontrarse almacenando estas claves en un dispositivo que siempre llevemos con nosotros y que permita almacenar las contraseñas de manera segura, lo que implica que si alguien que no somos nosotros accede al dispositivo no pueda disponer de ellas. Entre estos dispositivos podemos encontrar Blackberrys o PDAs, que disponen de software con esta funcionalidad, entre otros. Aún así no todos los usuarios disponemos de este tipo de dispositivos, y plantearse una inversión en un “trasto” así para únicamente almacenar las contraseñas no parece del todo coherente. Entonces cabe plantearse la siguiente pregunta: ¿existe algún dispositivo que todo usuario lleve siempre consigo y en el cual almacenar las claves pueda ser rápido, cómodo y seguro? Esta pregunta hoy en día tiene respuesta: el móvil.
La solución a este problema puede encontrarse almacenando estas claves en un dispositivo que siempre llevemos con nosotros y que permita almacenar las contraseñas de manera segura, lo que implica que si alguien que no somos nosotros accede al dispositivo no pueda disponer de ellas. Entre estos dispositivos podemos encontrar Blackberrys o PDAs, que disponen de software con esta funcionalidad, entre otros. Aún así no todos los usuarios disponemos de este tipo de dispositivos, y plantearse una inversión en un “trasto” así para únicamente almacenar las contraseñas no parece del todo coherente. Entonces cabe plantearse la siguiente pregunta: ¿existe algún dispositivo que todo usuario lleve siempre consigo y en el cual almacenar las claves pueda ser rápido, cómodo y seguro? Esta pregunta hoy en día tiene respuesta: el móvil.